Generating MCP tools from OpenAPI: benefits, limits and best practices
Generating MCP tools from OpenAPI: benefits, limits and best practices
AI agents are becoming a standard part of software interaction. From Claude Desktop assisting with research to custom agents automating workflows, these tools need a reliable way to interact with external data.
This is where the Model Context Protocol (MCP) comes in. Introduced by Anthropic in November 2024, MCP provides a universal standard for connecting AI agents to APIs and data sources. Think of it as the bridge between natural language and your API endpoints.
If you already have an API documented with OpenAPI, you’re in luck. An ecosystem of tooling has sprung up that can automatically generate a functional MCP server from your existing OpenAPI document. However there are limits to what’s possible and open questions about what good practice looks like.
In this guide, we’ll explore how to optimize your OpenAPI document for MCP server generation and look at tools that make this possible.
From OpenAPI to MCP: Where generators fit in
Now, why does this matter if you already have an OpenAPI document? Because, conceptually, OpenAPI specs already contain everything needed to create API-based MCP tools:
- Endpoint paths and methods define what operations are available
- Parameters and request schemas specify what inputs each operation needs
- Response schemas describe what data comes back
- Operation descriptions explain the purpose of each endpoint
An MCP generator transforms your OpenAPI specification into a functioning MCP server that exposes your API endpoints as tools AI agents can use:
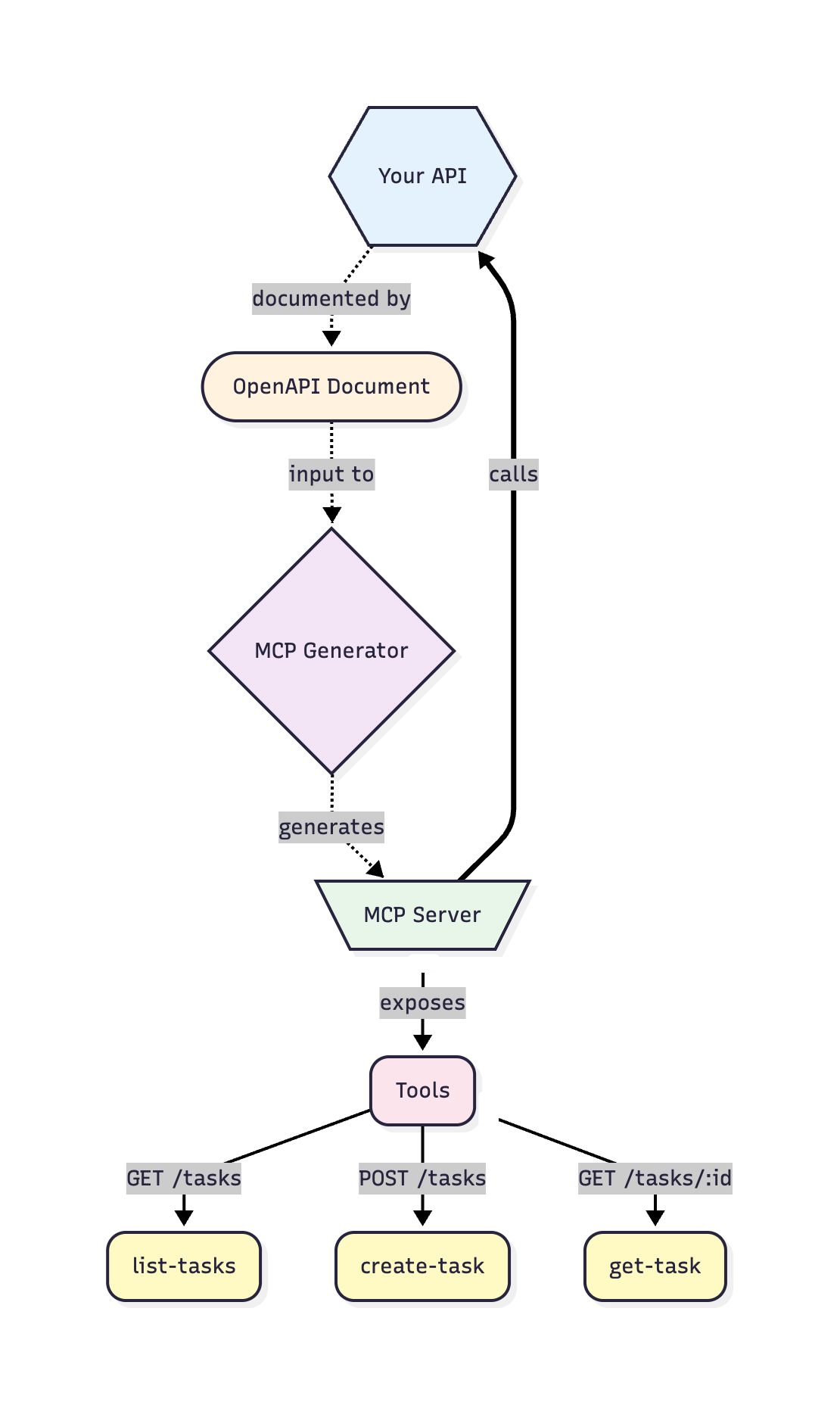
Your OpenAPI document serves as the source of truth, with its operations documented in OpenAPI format. An MCP generator reads this document and automatically creates tool definitions for each endpoint. The generated MCP server then acts as a bridge, translating AI agent requests into proper API calls. AI agents can discover and use your API’s capabilities through the MCP server, without needing to understand your API’s specific implementation details.
Your OpenAPI document becomes the single source of truth, eliminating the need to manually maintain two separate specifications. Your MCP server stays in sync with your API automatically.
Tools for generating MCP servers from OpenAPI documents
Three platforms and tools automatically generate MCP servers from OpenAPI documents:
- Gram is a managed platform made by Speakeasy that provides instant hosting and built-in toolset curation.
- FastMCP is a Pythonic framework that converts OpenAPI specs and FastAPI applications into MCP servers with minimal code.
- openapi-mcp-generator is an open-source CLI tool that generates standalone TypeScript MCP servers.
These tools differ primarily in their hosting models. Managed platforms like Gram and FastMCP Cloud handle hosting and infrastructure for you - on Gram you upload your OpenAPI document and you get an instantly accessible MCP server. Self-hosted tools like openapi-mcp-generator generate code that you deploy and run yourself, giving you full control over infrastructure, customization, and deployment.
Here’s how they compare across hosting model and automation level:
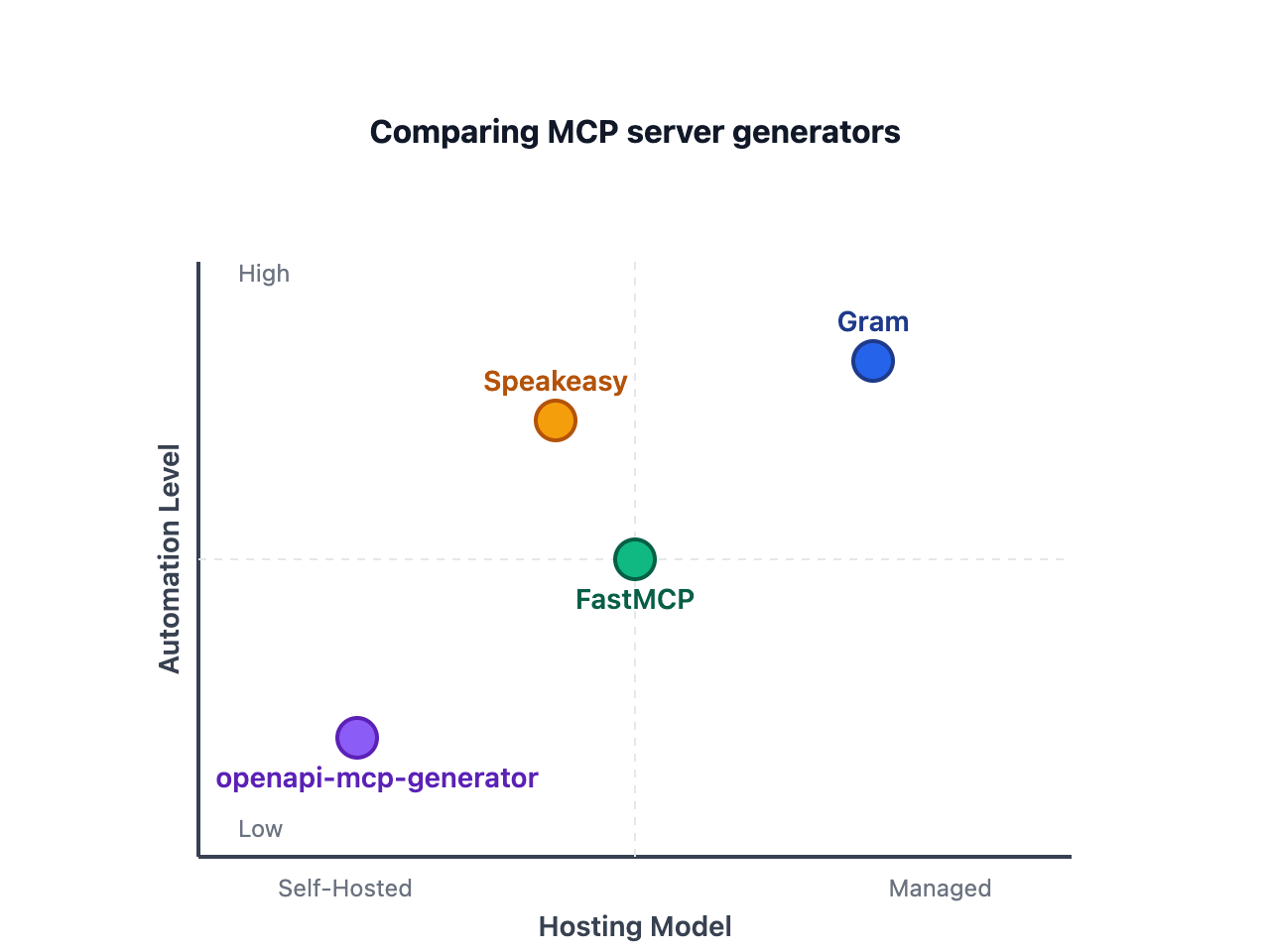
Gram offers the fastest path to production with a fully managed platform - no infrastructure to maintain. FastMCP gives you both options: use the Python framework for self-hosted servers or FastMCP Cloud for managed hosting. openapi-mcp-generator generates standalone TypeScript servers for complete self-hosted control.
MCP server generators comparison
Here’s a more detailed comparison of the features of each:
| Feature | Gram | FastMCP | openapi-mcp-generator |
|---|---|---|---|
| Language | N/A (hosted) | Python | TypeScript |
| Setup complexity | Low | Low | Low |
| Customization | Config-based | Programmatic | None |
| Tool curation | Yes, built-in | Programmatic | None |
| Hosting | Managed | Self-hosted/Managed | Self-hosted |
| Type safety | N/A | Partial | Full (Zod) |
| SDK generation | No | No | No |
| Auth handling | OAuth 2.0 | Manual config | Env variables |
| Test clients | Playground | No | HTML clients |
The problem: When LLMs hallucinate with poor OpenAPI documentation
Even the best AI models can confidently make things up when working with poorly documented APIs. This hallucination problem gets especially bad with MCP servers built from thin OpenAPI documents.
Suppose we ask a seemingly straightforward question like, “What was Lance Stroll’s fastest lap at Silverstone?”. Here’s what can happen with insufficient API documentation, especially problematic since Lance Stroll isn’t even in the database.

In this example, rather than returning an error or saying it doesn’t know, Claude uses the lapsPostLap tool to create a completely new (and fictional) lap record for Lance Stroll at Silverstone.
This happens because:
-
Endpoint purpose is unclear: Without explicit documentation about the purpose of each endpoint, the LLM can’t determine which tool to use and when.
-
Parameter documentation has gaps: Vague parameter descriptions may lead the LLM to misjudge expected formats and values, resulting in incorrect assumptions about a tool’s intended purpose.
-
Context is missing: Without examples of real response patterns, the AI can’t infer what expected data looks like, resulting in incorrect assumptions about the API’s behavior.
-
Error guidance is insufficient: Poor error documentation prevents the AI from recognizing when additional context or clarification is needed, leading to more hallucinations.
The good news? These problems can mostly be avoided by structuring your MCP tools well and following a few simple guidelines when writing your OpenAPI document.
How to optimize your OpenAPI document for MCP
Regardless of which tool you choose, the quality of your resulting MCP tools depends on the quality of your OpenAPI document. AI agents need more context than human developers to use APIs effectively.
Prompt engineering is most of the work when it comes to getting good results from AI models. Similarly, the clearer and more structured your OpenAPI documentation is, the more effectively AI tools will be able to understand and use your API.
Try these simple strategies to enhance your OpenAPI document and make it easier for AI models to interact with your API through MCP.
Write for AI agents, not just humans
Humans can infer context from brief descriptions. AI agents cannot. Compare these descriptions:
Basic description (for humans):
get: summary: Get task description: Retrieve a task by IDOptimized description (for AI agents):
get: summary: Get complete task details description: | Retrieves full details for a specific task including title, description, priority level (low/medium/high), current status, assignee, due date, and creation/update timestamps.
Use this endpoint when you need complete information about a task. If you only need a list of task IDs and titles, use listTasks instead.The optimized version tells the AI agent what data to expect in the response, when to use this endpoint vs alternatives, and what each field means (priority values, status types).
Provide clear parameter guidance
Include examples and explain constraints:
parameters: - name: task_id in: path required: true schema: type: string format: uuid description: | The unique identifier for the task. Must be a valid UUID v4. You can get task IDs by calling listTasks first. examples: example1: summary: Valid task ID value: "550e8400-e29b-41d4-a716-446655440000"Add response examples
Example responses help AI agents understand what successful responses look like:
responses: "200": description: Task retrieved successfully content: application/json: schema: $ref: "#/components/schemas/Task" examples: complete_task: summary: Task with all fields populated value: id: "550e8400-e29b-41d4-a716-446655440000" title: "Review Q4 goals" description: "Review and update quarterly objectives" priority: "high" status: "in_progress" assignee: "alice@example.com" due_date: "2025-10-15" created_at: "2025-10-01T09:00:00Z" updated_at: "2025-10-07T14:30:00Z"Use descriptive operation IDs
Operation IDs become tool names. Make them clear and action-oriented:
# GoodoperationId: createTaskoperationId: listActiveTasksoperationId: archiveCompletedTasks
# Less clearoperationId: post_tasksoperationId: get_tasks_listoperationId: update_task_statusEvery API operation should have a unique, descriptive operationId that clearly indicates its purpose. This naming convention helps AI models accurately map natural language requests like, “What’s Hamilton’s fastest lap?” to the correct tool, since the operationId is used as the default tool name.
Document error responses
Help AI agents understand what went wrong:
responses: "404": description: | Task not found. This usually means: - The task ID is incorrect - The task was deleted - You don't have permission to view this task content: application/json: schema: $ref: "#/components/schemas/Error"Optimize MCP tools with x-speakeasy-mcp
Speakeasy provides a dedicated OpenAPI extension specifically for customizing your MCP tools. The x-speakeasy-mcp extension gives you fine-grained control over how your API operations are presented to AI agents, allowing you to:
- Override tool names and descriptions
- Group related tools with scopes
- Control which tools are available in different contexts
Here’s how to use this extension:
paths: /tasks: post: operationId: createTask summary: Create a new task x-speakeasy-mcp: name: "create_task_tool" description: | Creates a new task in the task management system. Use this when the user wants to add a new task or todo item. Requires a title and optionally accepts a description and priority level. scopes: [write, tasks]This allows you to provide AI-specific descriptions and organize tools using scopes.
Customize tool names and descriptions
While a good operationId is great for SDK generation, MCP tools sometimes benefit from more descriptive names:
"/race-results/summary": get: operationId: getRaceSummary summary: Get race summary description: Retrieve a summary of race results # Default MCP tool will use these values"/race-results/summary": get: operationId: getRaceSummary summary: Get race summary description: Retrieve a summary of race results x-speakeasy-mcp: name: "get_race_finish_positions" description: | Get the final positions of all drivers in a specific race. Returns each driver's finishing position, total time, and points earned. Use this tool when you need to know who won a race or how drivers performed.The improved MCP tool name and description provide clearer guidance to AI agents about what the endpoint does and when to use it while preserving your API’s original structure.
Organize tools with scopes
Scopes let you control which tools are available in different contexts:
paths: /tasks: get: x-speakeasy-mcp: scopes: [read] post: x-speakeasy-mcp: scopes: [write] /tasks/{id}: delete: x-speakeasy-mcp: scopes: [write, destructive]Start the server with specific scopes:
# Read-only modenpx mcp start --scope read
# Read and write, but not destructive operationsnpx mcp start --scope read --scope writeIf you’re using Claude Desktop, you can also specify scopes in the config:
{ "mcpServers": { "RacingLapCounter": { "command": "npx", "args": [ "-y", "--package", "racing-lap-counter", "--", "mcp", "start", "--scope", "read", "--scope", "write" ] } }}Apply scopes across multiple operations
To apply scopes consistently across many operations, you can use the global x-speakeasy-mcp extension:
x-speakeasy-mcp: scope-mapping: - pattern: "^get|^list" scopes: [read] - pattern: "^create|^update" scopes: [write] - pattern: "^delete" scopes: [write, destructive]This automatically applies scopes based on operation name patterns, saving you from manually tagging each endpoint.
Add detailed parameter descriptions and examples
To make it easier for AI models to understand your MCP tools, provide detailed descriptions for each parameter. This includes specifying the expected format, constraints, and examples. This helps the LLM choose the right tools when it needs to follow a step-by-step approach to accomplish a task.
parameters: - name: driver_id in: path required: true schema: type: string description: | The UUID of the driver to retrieve. Must be a valid UUID v4 format. format: uuid examples: hamiltonExample: summary: Lewis Hamilton's ID value: f1a52136-5717-4562-b3fc-2c963f66afa6 verstappenExample: summary: Max Verstappen's ID value: c4d85b23-9fe2-4219-8a30-72ef172e327b title: Driver Id description: The UUID of the driver to retrieve x-speakeasy-mcp: description: | The unique identifier for the driver. You can find the IDs of current F1 drivers by first using the listDrivers tool. Common drivers include Lewis Hamilton, Max Verstappen, and Charles Leclerc.Add examples to responses
To improve the LLM’s understanding of your API’s responses, provide detailed descriptions, examples, and expected structures. This helps the LLM accurately interpret the data returned by your API.
responses: "200": description: | Lap records retrieved successfully, sorted from fastest to slowest lap time. Returns an empty array if the driver exists but has no recorded laps. content: application/json: schema: type: array items: "$ref": "#/components/schemas/Lap" title: DriverLapsResponse examples: multipleLaps: summary: Multiple lap records value: - id: "3fa85f64-5717-4562-b3fc-2c963f66afa7" lap_time: 85.4 track: "Silverstone" - id: "3fa85f64-5717-4562-b3fc-2c963f66afa8" lap_time: 86.2 track: "Monza" emptyLaps: summary: No lap records value: [] x-speakeasy-mcp: name: "get_driver_lap_records" description: | Returns an array of lap records for the requested driver. Each record contains: - id: A unique identifier for the lap record - lap_time: Time in seconds (lower is better) - track: Name of the circuit where the lap was recorded
The records are sorted from fastest to slowest lap time. If the driver exists but hasn't completed any laps, this will return an empty array.Conclusion
Generating MCP servers from OpenAPI documents bridges the gap between your existing APIs and AI agents. With an OpenAPI document you can have a working MCP server in minutes instead of days.
While this guide focuses on optimizing your OpenAPI document for MCP servers, these techniques are also good practice for writing well-structured, high-quality, comprehensive OpenAPI documents with great developer experience.
Ready to get started? Try Gram for instant managed hosting, explore FastMCP for Python-based development, or use openapi-mcp-generator for a self-hosted TypeScript solution.
For more information on how to improve your OpenAPI document, check out our OpenAPI best practices guide.