The Mythos security story is only half told
Cameron McClellan
June 12, 2026 · 11 min read

When details of Anthropic's Claude Mythos leaked in April, investors wiped double-digit percentages off major cybersecurity vendors in days, with Akamai down 20% and CrowdStrike and Palo Alto Networks not far behind. The market had reached a verdict on what frontier AI means for security: attackers win.
Six weeks later, Anthropic reported that defenders using the same model had found more than 10,000 high and critical severity vulnerabilities in a single month, including 2,000 bugs at Cloudflare with a false positive rate its team called better than human testers, and 271 fixes shipped in a single Firefox release. That result ran in the security trade press and almost nowhere else.
Those two stories describe one model. The first dominated front pages, moved markets, and triggered congressional briefings. The second is being told mostly by the vendors running the programs, to an audience of practitioners. Arguing over which half wins is a way to avoid the part an enterprise can act on. Whether frontier capability tilts toward attack or defense, the same capability now sits inside the agents the enterprise already runs, and the job is to govern those agents before it is turned against them. The controls that do it are unglamorous, available now, and increasingly non-optional.
What can Mythos-class models actually do in cybersecurity?
The capability jump is the largest single-generation jump in offensive security evaluations to date. Anthropic's Frontier Red Team disclosure reported that Mythos produced 181 working Firefox JavaScript engine exploits where the previous generation, Opus 4.6, produced two. It found zero-days autonomously, including a 27-year-old signed integer overflow in OpenBSD's TCP stack and a 16-year-old FFmpeg flaw, and it turned known vulnerabilities into working exploits for under $2,000 each.
The independent evaluation matched the vendor's. The UK AI Security Institute scored Mythos at 73% on expert-level capture-the-flag challenges and watched it become the first model to complete the institute's 32-step network attack simulation end to end. The institute's bottom line was carefully bounded: Mythos can autonomously attack small, weakly defended enterprises, and remains unproven against hardened, actively defended environments. Nor is the capability unique to one lab. The same institute rated OpenAI's GPT-5.5 among the strongest models it has tested on cyber tasks.
Anthropic responded by not releasing the model publicly. Mythos access went to vetted partners through Project Glasswing, a program built to harden critical software before the capability becomes broadly available, while the public got Claude Fable 5, the same model class with classifier safeguards on cyber capabilities.
How is the Mythos security story being told?
We cataloged the substantial Mythos coverage since April, and the split is stark. Stories framed around offensive risk outnumber defense-framed pieces roughly two to one by count, and the imbalance widens sharply when weighted by audience: the offense narrative ran on CNBC, in the Wall Street Journal, and across the financial press, while the defense results ran in Dark Reading, SecurityWeek, and vendor blogs.
The offense narrative owns the headlines
The offense coverage runs in the loudest venues. TechCrunch covered the Fable 5 release under a headline noting it came days after Anthropic warned AI was getting too dangerous. Axios reported that Mythos turns fresh patches into working exploits in hours. The House Homeland Security Committee took a closed-door briefing with a live demonstration, 32 House members pressed the National Cyber Director for a response plan, and the Wall Street Journal reported that the White House opposed expanding Mythos access. The market selloff put a dollar figure on the fear.
The defense results are quieter, not smaller
The quiet half has numbers at least as striking. In Glasswing's first month, partners found over 10,000 high and critical vulnerabilities across codebases that include AWS, Apple, Cisco, Google, Microsoft, and the Linux Foundation. Palo Alto Networks used its access to scan more than 130 of its own products and shipped 26 CVE fixes in a month, against a typical rate below five. The pattern predates Mythos: Google's Big Sleep agent found a SQLite flaw before threat actors could exploit it, the first claimed AI preemption of in-the-wild exploitation, and Anthropic's own security scanning found 500+ vulnerabilities in production open source projects back in February. In June, Glasswing expanded to 150 more organizations across critical infrastructure in 15 countries.
The defense story has honest weaknesses, which is part of why it travels badly. As of the May update only a small fraction of the 10,000 findings had upstream patches, a gap Bruce Schneier and others have pressed hard on: finding vulnerabilities at machine speed only helps if patching accelerates too. And much of the defense narrative is authored by the vendors running the programs, which invites discounting even when the underlying numbers, like Mozilla's 271 fixed Firefox flaws, are independently verifiable.
There is a third thread that shows how lopsided framing produces real costs: security researchers publicly complained that Fable 5's guardrails block legitimate defensive work. When the public conversation treats capability purely as a weapon, the policy response restricts defenders along with attackers.
Does frontier AI favor attackers or defenders?
The most credible neutral voices land on a conditional answer. Schneier's assessment is that the advantage goes to defense eventually in systems that are easy to patch and verify, like browsers and major cloud services, with dangerous windows for slow-patching systems like vehicles, grids, and legacy banking. The UK National Cyber Security Centre's CEO argues AI vulnerability discovery can ultimately be good for cybersecurity, provided suppliers actually use it across their product lifecycles.
Both conditions point the same direction: AI favors whichever side operationalizes it first. Capability is symmetric. Adoption is not. The offense needs one ungoverned path in; the defense needs the discipline to find and close its own paths first, and the window to do it in is shrinking. Palo Alto Networks estimates three to five months before AI-driven exploitation goes broad.
What does Mythos-class capability mean for enterprise AI security?
The headline Mythos results, the Firefox engine exploits and the OpenBSD and FFmpeg zero-days, are not an enterprise's problem to solve. They live in shared software upstream of any one company, and they get closed by the vendors who own that code and by programs like Glasswing. No amount of internal diligence patches a browser flaw faster, and tracking the attack-and-patch cycle is not where an enterprise has leverage.
Where it does have leverage is its own house. The sharpest implication for an enterprise is not that outside attackers got better tools, although they did. It is that the agents already inside the walls got more capable, and an agent's capability flows to whoever controls its context.
That is not hypothetical. Anthropic's disclosure of the first AI-orchestrated espionage campaign documented a state-sponsored group using Claude Code and MCP-connected tools against roughly 30 organizations, with 80% to 90% of the tactical work executed by the AI. In May, Sysdig documented the first in-the-wild LLM-agent-driven post-exploitation: from a fresh CVE to a fully exfiltrated internal database in under an hour, through four pivots, with no human at the keyboard. Every increment of model capability raises what a hijacked or misdirected agent can accomplish in the same way it raises what a well-directed one can.
The analyst world has already named the category this creates. Gartner put AI security platforms on its top strategic technology trends for 2026, covering prompt injection, data leakage, and rogue agent actions, and predicts more than half of enterprises will run one by 2028.
Internal AI governance is already buildable
The enterprise response is not a counter-Mythos weapon, and it does not wait on the labs. It is a governance program over the AI an organization already runs, and it would be worth building even if no Mythos-class attack ever arrived: the agents inside the walls need bounded access, inspected inputs and outputs, and an audit trail regardless. The attack and defense headlines sit adjacent to that work. They raise its urgency without changing its shape. None of the program is exotic, and none of it lives in the model. It lives on the path between agents and everything agents touch, which is what the AI Control Plane is. The diagram below shows the four checkpoints on that path.
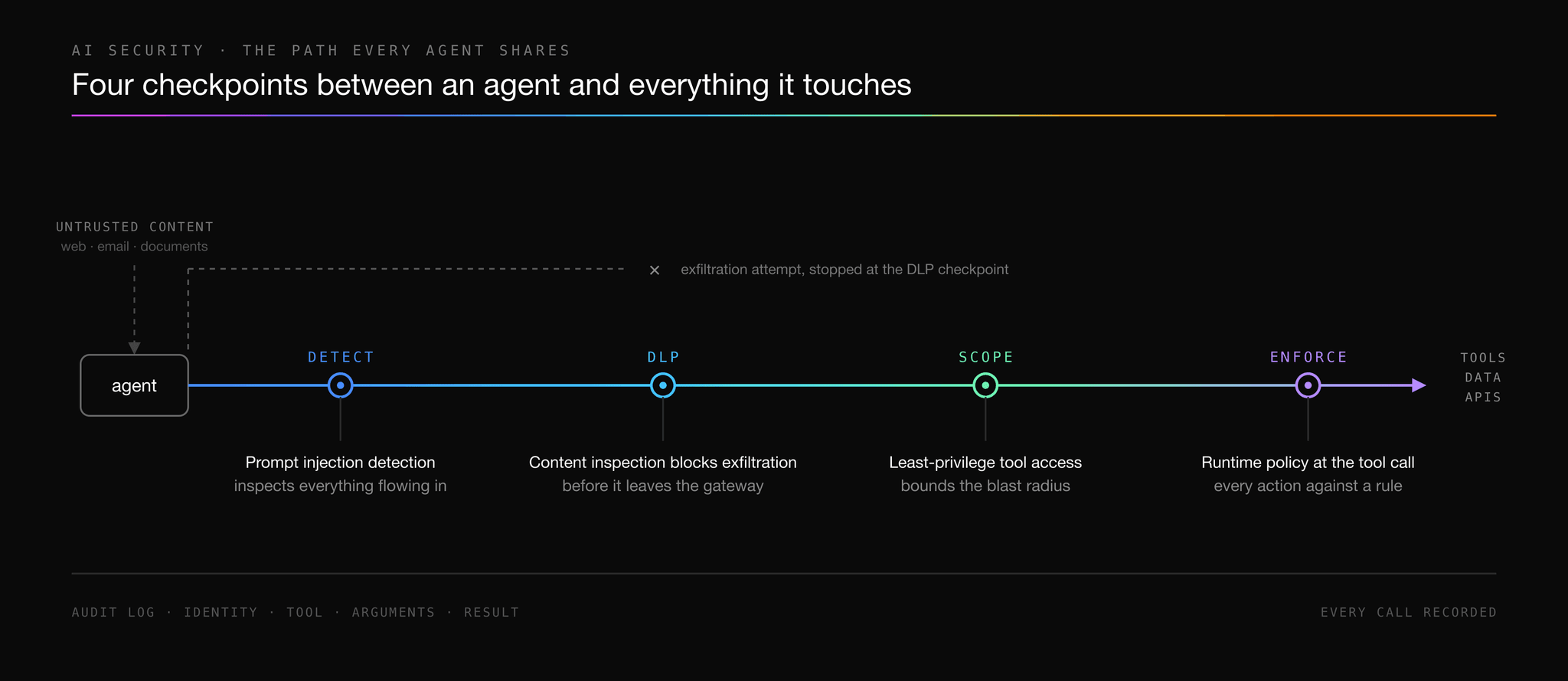
Each control closes a way an internal agent can be turned against the organization or leak on its own:
- Prompt injection detection inspects what flows into an agent, because the documented agent-driven attacks begin by turning the agent's own context against it.
- DLP for agents inspects what flows out, so a misdirected agent cannot exfiltrate what the gateway refuses to pass.
- Scoped tool access through an MCP gateway keeps every agent at least privilege, so the blast radius of a compromised agent is the handful of tools it was granted, not everything its credentials can reach.
- Runtime policy enforcement applies rules at the tool-call boundary, where an agent's intent becomes an action, with every call landing in an audit log that makes the after-action review a query instead of a forensics project.
Speakeasy ships these controls as the AI Control Plane, and the argument for them is exactly the asymmetry this post describes. Model capability will keep rising on both sides of the ledger, on whatever schedule the labs set. What an enterprise controls is whether its own agents operate governed or ungoverned when that capability arrives. The offense half of the Mythos story says the stakes went up. The defense half says the tools work. Both halves end in the same place: the time to put a control plane between your agents and your systems is before the window Palo Alto is measuring in months runs out.
Further reading
- The AI Control Plane: the reference architecture for governing AI across an organization, function by function.
- Where Claude falls short in AI security: what the model vendor's own controls cover, and where the gateway layer has to take over.
- The OWASP Agentic Top 10, explained: the threat categories that scoped tool access and runtime policy are built against.
- The NSA's MCP security baseline: what formal government guidance on MCP security means for enterprise deployments.
What is Claude Mythos?
Claude Mythos is Anthropic's frontier model class with advanced cybersecurity capabilities, kept under restricted access rather than released publicly. Vetted partners use it through Project Glasswing to find and fix vulnerabilities in critical software, while the publicly available Claude Fable 5 is the same model class with classifier safeguards on cyber capabilities.
Is the security conversation about Mythos really one-sided?
Mostly. In our review of major coverage since April 2026, offense-framed stories outnumber defense-framed ones roughly two to one, and the gap widens when weighted by prominence: the offense narrative ran on CNBC, in the Wall Street Journal, and through congressional briefings, while defensive results like 10,000 vulnerabilities found in Glasswing's first month ran mainly in security trade press and vendor blogs.
Do more capable AI models help attackers or defenders more?
Capability itself is symmetric: the same model that writes exploits finds and fixes the underlying flaws. Analysts like Bruce Schneier expect defenders to win in systems that patch quickly and attackers to profit in slow-patching ones. In practice the advantage goes to whichever side operationalizes the capability first, which for enterprises means governing their own agents before attackers reach them.
How does an AI Control Plane defend against AI-powered attacks?
An AI Control Plane sits on the path between every agent and every system it can reach. It detects prompt injection in what flows into agents, applies DLP to what flows out, scopes each agent's tool access to least privilege through an MCP gateway, and enforces policy at the tool-call boundary with a full audit log. These controls bound what any single compromised or misdirected agent can do, regardless of how capable the underlying model is.
Last updated on