How to factor cost into agentic tool design
Sagar Batchu
August 21, 2025 · 10 min read
AI benchmarks have a giant blind spot: they celebrate agents that succeed at any cost. Admiring an agent’s position on today’s leaderboards is like praising a brute force search algorithm for its 100% success rate. If accuracy is the only metric, brute force is perfectly acceptable.
Bigger AI models win by throwing more parameters and reasoning cycles at problems, because this is what the benchmarks reward. Even a stopped clock is right twice a day, but that doesn’t make it a good timepiece.
New research from Bloomberg shows that by taking cost into account while optimizing tool descriptions and agent instructions, we can achieve similar or even better performance at a fraction of the cost.
The paper, A Joint Optimization Framework for Enhancing Efficiency of Tool Utilization in LLM Agents, introduces a new measure for how well language models use tools: Cost-Aware Pass Rate (CAPR). Instead of merely asking, “Did the model use the tool?” the study adds, “and at what cost?”
Anyone building agents or tools for agents could benefit from this research. We’ll summarize the key finding here and look at a practical example of how to implement the joint optimization framework for your own APIs and agents.
The research: Context vs inference scaling
The Bloomberg team tested their joint optimization framework across 16,464 APIs in StableToolBench, and against real-world scenarios in RestBench. They compared two fundamental approaches: Context optimization (improving instructions and tool descriptions) versus inference scaling (adding more reasoning steps, like Chain-of-Thought1 or tree search2).
The research suggests that context optimization leads to better performance and lower costs compared to inference scaling alone.
When agents only have access to vague tool descriptions, they often resort to trial-and-error approaches, stubbornly repeating slightly varied queries until they stumble on a successful one. Sophisticated reasoning algorithms can’t compensate for poor documentation.
Is this just prompt engineering?
Not quite. While improving prompts is an important part of the solution, tool descriptions may play a bigger role.
Perhaps the most surprising finding from this research is that only improving tool descriptions results in a bigger gain than only doing instruction tuning. While joint optimization (improving both tool descriptions and agent instructions) leads to the best outcomes, good tool descriptions can actually be more important than good prompts.
Why context quality matters more than we thought
LLMs select tools and make tool calls based entirely on the available context. Tools with incomplete or vague descriptions cause agents to iterate through multiple attempts before finding and using the right tool effectively.
This is compounded by incomplete instructions or guidance on how to use the tools.
When tools depend on each other, failures can cascade, leading to a situation where the agent’s inability to effectively use one tool impacts its interactions with others. Improving a single tool’s description can lead to better performance across a suite of interdependent tools.
Giving an agent more reasoning capabilities, like the ability to perform Chain-of-Thought reasoning about which tools to pick and how to use them, may reduce the impact of these issues. However, inference scaling doesn’t make up for missing context.
The research data shows that context optimization provides 10-30% cost reduction at fixed accuracy, while inference scaling increases costs by 200-500% for marginal accuracy gains.
Practical implementation: The joint optimization framework
Here’s how to implement the Bloomberg research team’s joint optimization approach for your own APIs and agents. The process works with any tool-calling system, whether it’s MCP servers, function calling, or custom APIs.
The challenge: Generic tool descriptions
Most API documentation follows patterns like these:
listItems: “List all items”createItem: “Create a new item”updateItem: “Update an item”deleteItem: “Delete an item”
While technically accurate, these descriptions don’t help LLMs choose between similar operations, understand required parameters, or handle edge cases effectively.
Step 1: Establish baseline measurement
First, connect your agent to your existing API and collect interaction data. The key is measuring both success and efficiency:
# Connect your agent to your API (adapt to your setup)agent = YourAgent( system_prompt="Your current system prompt", tools=your_existing_tools)
# Test with realistic user queriestest_queries = [ "Create a new task called 'Review quarterly reports'", "Show me all my current tasks", "Update the first task to mark it as high priority", "Delete any completed tasks"]
# Collect performance datafor query in test_queries: interaction = await agent.process_query(query) # Log: query, tools called, success rate, response timeWhat to measure:
- Success rate: Did the agent complete the task correctly?
- Tool call efficiency: How many API calls were needed?
- Response time: How long did each interaction take?
- Error patterns: Which operations consistently fail?
Step 2: Calculate the Cost-Aware Pass Rate (CAPR)
Unlike traditional success metrics, CAPR penalizes inefficient tool usage:
def calculate_capr(interactions, efficiency_threshold=5): scores = [] for interaction in interactions: success = interaction.success tool_calls = len(interaction.tool_calls)
if tool_calls > efficiency_threshold: scores.append(0) # Too inefficient else: efficiency = 1 - (tool_calls / efficiency_threshold) scores.append(success * efficiency)
return sum(scores) / len(scores)Step 3: Apply joint optimization
The Bloomberg framework optimizes both system prompts and tool descriptions together:
# Analyze current performance patternsanalysis = analyze_interactions(interactions)
# Generate coordinated improvementsoptimized_prompt, optimized_tools = joint_optimization( interactions=interactions, current_prompt=your_system_prompt, current_tools=your_tool_descriptions)Step 4: Update your tool documentation
Apply the optimized descriptions to your tool documentation, depending on how your tools are defined.
For example, if your tools are part of a Gram-hosted MCP server, update tool descriptions in the Gram admin interface or directly in the OpenAPI documents.
Step 5: Validate improvements
Test your optimized agent with the same queries to measure improvements.
Example: TODO MCP server hosted by Gram
As an example, we tested the joint optimization framework on a TODO MCP server hosted by Gram. Here’s the step-by-step process we followed, including the results we obtained.
Step 1: Initial server setup
We started with a basic TODO API hosted on Gram with these generic tool descriptions:
listTodos: “List all todos”createTodo: “Create a new todo”updateTodo: “Update a todo”deleteTodo: “Delete a todo”
The OpenAPI document contained minimal descriptions that provided no parameter guidance or usage examples.
Step 2: Connect the optimization agent
We created a simple Python agent that connects to the Gram MCP server:
from pydantic_ai import Agentfrom pydantic_ai.mcp import MCPServerStreamableHTTP
agent = Agent( model='gpt-4o-mini', system_prompt="You help users manage their todo lists efficiently.", toolsets=[ MCPServerStreamableHTTP( url="https://app.getgram.ai/mcp/todo-example" ) ])Step 3: Collect baseline performance data
We tested the agent with realistic user queries:
test_queries = [ "Add 'Buy groceries' to my todo list", "Show me all my todos", "Add 'Call dentist' to my todos", "Mark the first todo as completed", "Show me my todos again", "Delete the completed todo"]Here are the baseline results:
- Success rate: 83.3% (5 out of 6 queries succeeded)
- Average response time: 8.36 seconds
- CAPR score: 0.833
- Key failure: The delete operation failed because the agent couldn’t determine which todo to delete without specific ID guidance
Step 4: Run the optimization analysis
Using the Bloomberg team’s joint optimization framework, we analyzed the interaction data:
# Convert our interaction logs to the optimization formatoptimization_interactions = convert_to_optimization_format(interactions)
# Extract current tool descriptions from the OpenAPI speccurrent_descriptions = extract_tool_descriptions_from_openapi(openapi_spec)
# Run the joint optimizationoptimized_prompt, optimized_tools = joint_optimization( optimization_interactions, current_system_prompt, current_descriptions)The analysis identified specific improvements for both the system prompt and tool descriptions.
For example, here’s how the system prompt can be enhanced:
- Before: “You help users manage their todo lists efficiently.”
- After: “You help users manage their todo lists efficiently. Use specific commands like ‘Add’, ‘Show’, ‘Update’, ‘Replace’, or ‘Delete’ followed by the task details. For example, you can say ‘Add task X’ to create a new todo or ‘Show my todos’ to list all todos.”
And here’s how tool descriptions can be improved:
| Tool | Original Description | Optimized Description |
|---|---|---|
deleteTodo | ”Delete a todo" | "Delete a todo by ID. Example usage: deleteTodo(18) to remove the todo with ID 18.” |
updateTodo | ”Update a todo" | "Update a todo by ID. Example usage: updateTodo(1, ‘New details’) to change the details of the todo with ID 1.” |
createTodo | ”Create a new todo" | "Create a new todo. Example usage: createTodo(‘New task description’) to add a new task.” |
listTodos | ”List all todos" | "List all todos. Example usage: listTodos() to retrieve all current todos.” |
Step 5: Generate the optimized OpenAPI document
The framework automatically generated an updated OpenAPI document with Gram’s x-gram extensions:
paths: /todos/{id}: delete: operationId: deleteTodo summary: Delete a todo x-gram: name: deletetodo description: 'Delete a todo by ID. Example usage: deleteTodo(18) to remove the todo with ID 18.' put: operationId: updateTodo summary: Update a todo x-gram: name: updatetodo description: 'Update a todo by ID. Example usage: updateTodo(1, "New details") to change the details of the todo with ID 1.'Step 6: Update the Gram server
Next, we updated the Gram server configuration. To do this yourself:
- Log in to the Gram dashboard.
- Navigate to Toolsets.
- Click on the API Source you’re updating, then select Update in the dropdown menu.
- Upload the optimized OpenAPI document.
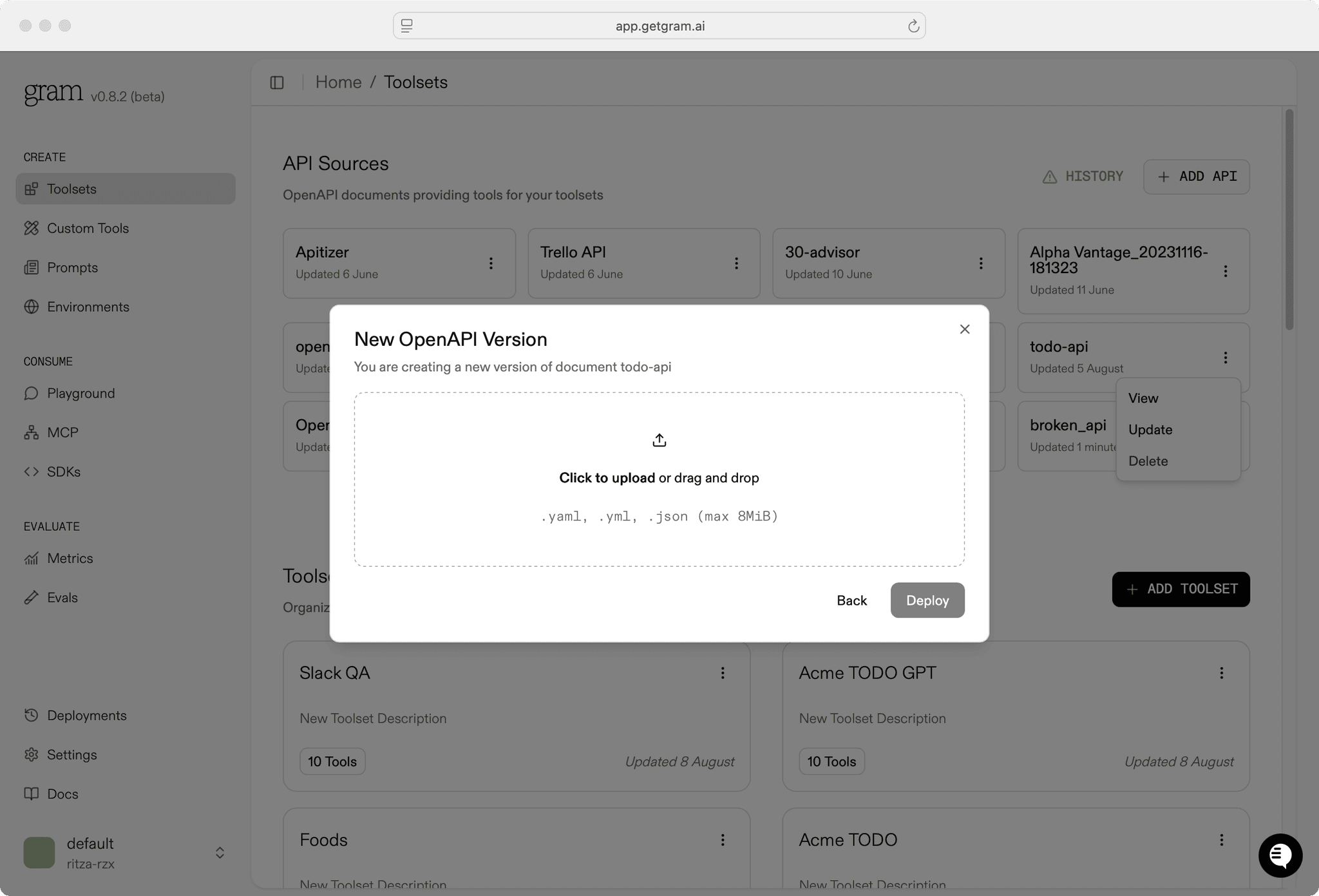
The new descriptions will apply to any MCP servers using tools from the updated API Source.
Step 7: Test the optimized server
After deploying the updated server, we ran the same test queries to measure improvements. Our example query for deleting a todo item performed better with clear parameter guidance, resulting in a higher success rate and faster response time.
Implementing CAPR and joint optimization for your tools
The Bloomberg research repository contains the complete code for Bloomberg’s CAPR and joint optimization framework, including benchmarks. To implement similar optimizations for your own tools, follow these steps:
- Analyze your interaction data: Collect and analyze user interactions with your tools to identify common failure points and areas for improvement.
- Define clear tool descriptions: Ensure that each tool has a clear and specific description, including example usage patterns.
- Incorporate usage examples: Add usage examples to your tool descriptions to clarify expected input formats and behaviors.
- Test and iterate: Continuously test your tools with real user queries, gather feedback, and iterate on your descriptions and prompts to improve performance.
Risks when implementing CAPR and joint optimization
The research revealed an unexpected insight: Verbalized optimization can overfit just like traditional machine learning. After two to three optimization iterations, tool call counts began to increase again despite maintaining accuracy.
There isn’t a clear solution to this problem yet, but we recommend tracking efficiency metrics closely to identify potential overfitting early.
Practical next steps
If you’re building agents and tools for your organization, consider updating your AI tool usage metrics to take cost into account. This is essential to optimizing for efficiency and effectiveness.
If you maintain MCP servers, we recommend implementing similar strategies to optimize your servers’ tool descriptions. You could also make it easier for users to customize your tools’ descriptions to better fit their specific needs.
At Speakeasy, we’re following this research closely and building the infrastructure to enable our users to curate, measure, and optimize their MCP servers effectively.
Footnotes
-
Chain-of-Thought (CoT) encourages models to generate intermediate reasoning steps before arriving at a final answer. Rather than jumping directly to conclusions, CoT prompts guide models to “think out loud” through problems step by step, significantly improving performance on complex arithmetic, commonsense, and symbolic reasoning tasks. ↩
-
Tree search methods like depth-first search (DFS) extend linear reasoning approaches by exploring multiple solution paths simultaneously. When applied to LLM tool use, these methods maintain a backup mechanism to quickly restart from the last successful state when a tool call fails, theoretically improving both effectiveness and efficiency compared to simple retry strategies. ↩
Last updated on