Prompting agents: What works and why
Nolan Sullivan
September 23, 2025 · 19 min read
Prompting agents: What works and why
As chatbots, large language models are surprisingly human-like and effective conversation partners. They mirror whoever is chatting with them and have a knack for small-talk like no other - sometimes even appearing too compassionate.
In contrast, working with an LLM agent (rather than a chatbot) often feels like you’re pushing a string, only to realize too late that the string has folded over itself in kinks and loops, and you need to start over again. Agents that lack clear success and failure criteria or explicit direction can be expensive, slow, and in the worst case, destructive.
In this guide, we unpack the different layers of prompting agents, and explore proven methods for improving how we prompt agents.
But first, why focus on agents if there is already so much written about prompts and context engineering in general?
Chatbots are for loops; agents are while loops
Chatbots take discrete turns, with a human available to steer the bot at each turn. They work on a single task per turn. Claude, ChatGPT, and Grok are examples of chatbots. There are many prompting guides available online for these popular chatbots.
Agents, on the other hand, work continuously in a loop to achieve complex goals. Agents are usually employed in situations where they have access to tools that influence the real world. Examples include Claude Code, ChatGPT Operator (soon to be replaced by ChatGPT agent mode), and Gemini CLI. Agents are so complex, layered, and multifaceted that most agent prompting guides only scratch the very surface - how an end user should ask an agent to do things.
A note on terminology
The AI world hasn’t settled on standard terms yet (even calling LLMs “AI” is sometimes frowned upon), so let’s be clear about what we mean:
Agents are AI systems that can take actions through tools - they can run commands, manipulate files, call APIs, and change things in the real world. Claude Code executing terminal commands is an agent. When Cursor edits your files or Gemini CLI runs Python scripts, they are also acting as agents.
Agent interfaces like Claude Code, ChatGPT Operator, and Gemini CLI are the products you interact with. They combine an underlying model (Claude 3.5 Sonnet, GPT-4, Gemini) with tools and a user interface.
Chatbots just generate text responses. They can’t execute code, access your filesystem, or take actions beyond returning text. Regular Claude.ai and ChatGPT (without plugins) are chatbots.
When we talk about “prompting agents” we mean getting AI to actually do things, not just talk about doing them.
When prompting an agent, start at the right layer
An agent’s prompt doesn’t start at the point when a user asks a question. An agent prompt is a larger entity, which we can break up into the following distinct layers, all of which influence how well an agent performs, and each of which is as important as the others to get right:
-
The model’s platform-level instructions: At the highest layer are the platform-level instructions. These are set by the platform, like OpenAI or Anthropic. For example, even if we use the OpenAI API, the model’s API responses won’t include copyrighted media, illegal material, or information that could cause harm.
-
Developer instructions: These are often called the system prompt, and for most developers, this is the highest level of authority their prompts could have. Examples include proprietary system prompts, like Claude Code or Cursor’s system prompt, or prompts for open-source agents like those of Goose and Cline. The system prompt is set by the agent’s developers.
-
User rules: Some agents support rules files that the user can set for all instances of their agent. For example, Claude Code reads the file at
~/.claude/CLAUDE.md, or any parent directory of the project you’re working on, and consistently applies your rules to its actions. -
Project rules: These are instructions an agent applies within a specific directory. For example, a
CLAUDE.mdfile in the project root directory, or a child directory. -
User request: This is the actual prompt entered by the user, for example, “Fix the race condition in
agents/tasks.py”. -
Tool specifications: At the lowest level are the descriptions and guidelines from tool developers, which include input/output formats, constraints, and best practices. These are usually only for the agent to read and are written by the tool developers. An example would be the
browser_console_messagestool in Playwright MCP, with the descriptionReturns all console messages.
These different prompt levels are strung together in the agent’s context, and changing any one may have an effect on the agent’s performance. The levels you have access to and your history with the agent will determine where you should begin improving your prompts.
| Role | Description | Levels to influence |
|---|---|---|
| Agent user | The person interacting with the agent, providing input and feedback. | User request, User rules, Project rules. |
| Agent developer | The person building and maintaining the agent, responsible for its overall behavior and capabilities. | Developer instructions. |
| Model host | The underlying architecture and infrastructure that supports the agent, including APIs, databases, and other services. | Platform-level instructions. |
| Tool developer | The person or team responsible for creating and maintaining the tools that the agent uses. | Tool specifications. |
Understanding how system prompts shape agent behavior
You can’t change the system prompt of Claude Code or ChatGPT Operator, but understanding what’s happening behind the scenes helps explain why agents sometimes behave in unexpected ways and how to work around their limitations.
System prompts are the hidden instructions that make agents work. They’re written by the companies building these tools and run thousands of words long. When your agent refuses to do something reasonable or insists on doing something you didn’t ask for, the system prompt is often at work.
Here’s what these gigantic prompts typically contain:
1. Identity and role boundaries
Most agents start with a defined identity that constrains what they will and won’t do. This is why Claude Code won’t help you write malware, even if you have a legitimate security testing reason.
For example, Cline’s system prompt looks as follows (from their open-source code):
const AGENT_ROLE = [ "You are Cline,", "a highly skilled software engineer", "with extensive knowledge in many programming languages, frameworks, design patterns, and best practices.",]2. Tool usage patterns and guardrails
Agents have extensive instructions about how to use their tools correctly. This is why Claude Code often checks file contents before editing, or why it might refuse certain filesystem operations.
For example, the MinusX team discovered the contents of Claude Code’s hidden prompts:
<system-reminder>This is a reminder that your todo list is currently empty. DO NOT mention this to the user explicitly because they are already aware.</system-reminder>
<good-example>pytest /foo/bar/tests</good-example>
<bad-example>cd /foo/bar && pytest tests</bad-example>This structured XML approach dramatically improved tool usage accuracy and reduced navigation errors.
3. Domain-specific behaviors
Agents come preloaded with opinions about best practices. When v0 generates a React component, it follows specific instructions about which libraries to use and how to structure code.
For example, this is what v0 by Vercel is instructed to do behind the scenes:
- You use the shadcn/ui CHART components.- The chart component is designed with composition in mind.- You build your charts using Recharts components and only bring in custom components, such as ChartTooltip, when and where you need it.- You always implement the best practices with regards to performance, security, and accessibility.- Use semantic HTML elements when appropriate, like `main` and `header`.- Make sure to use the correct ARIA roles and attributes.- Remember to use the "sr-only" Tailwind class for screen reader only text.- Add alt text for all images, unless they are decorative or it would be repetitive for screen readers.The massive size and impact of system prompts
Modern AI coding agents use system prompts of around tens of thousands of characters. These prompts encode years of engineering wisdom, safety rules, and behavioral patterns.
Here’s what you need to keep in mind about these hidden instructions:
- Your instructions compete with these prompts: If you ask for something that conflicts with the system prompt, the system prompt usually wins.
- Weird behaviors often trace back here: That annoying habit where ChatGPT uses em-dashes everywhere? Probably baked into its system prompt.
- You can work around them once you know they exist: You can override default behaviors by being more explicit and repeating important instructions.
Want to see what’s under the hood? Check out these extracted system prompts from top AI tools (though be aware, these are often reverse-engineered and may not be official): Collection of system prompts.
Learning from open-source agents
If you’re building your own agent or want to understand how they think, these open-source system prompts are goldmines:
- The Goose system prompt
- The Cline system prompt
- Aider System Prompt
- The Zed prompts
- The Gemini CLI system prompt
Tracking how these prompts change over time reveals how agent capabilities evolve and the problems developers are trying to solve.
Now that you understand the hidden forces shaping agent behavior, let’s look at what you can actually control: your own prompts.
Prompting as a user: Techniques that improve agent performance
Let’s look at some examples of prompting techniques.
1. Give agents clear success criteria
Simon Willison, who has extensively documented his AI agent experiments, demonstrates this perfectly. In one function-writing experiment, he saved 15 minutes of work with an efficient prompt.
Simon could have used a simple prompt like the following:
Write a function to download a database from a URL.At a glance, we can guess how that conversation would have gone - a long loop of clarifying questions and incremental changes, eventually taking as long as it would have to just write the function ourselves.
Instead, he used a prompt that included success criteria:
Write a Python function that uses asyncio httpx with this signature:
async def download_db(url, max_size_bytes=5 * 1025 * 1025): -> pathlib.Path
Given a URL, this downloads the database to a temp directory and returns a path to it. BUT it checks the content length header at the start of streaming back that data and, if it's more than the limit, raises an error. When the download finishes it uses sqlite3.connect(...) and then runs a PRAGMA quick_check to confirm the SQLite data is valid—raising an error if not. Finally, if the content length header lies to us— if it says 2MB but we download 3MB—we get an error raised as soon as we notice that problem.This prompt produced a complete, production-ready function in 15 seconds. Simon’s key insight is that the prompt should do the following:
- Provide the exact function signature upfront.
- Specify the precise technologies to use.
- Follow up with “Now write me the tests using pytest” to get comprehensive test coverage.
2. Use the “think” tool pattern
Anthropic added a seemingly useless “think” tool that significantly improves complex reasoning:
{ "name": "think", "description": "Use the tool to think about something. It will not obtain new information or change the database, but just append the thought to the log. Use it when complex reasoning or some cache memory is needed.", "input_schema": { "type": "object", "properties": { "thought": { "type": "string", "description": "A thought to think about." } }, "required": ["thought"] }}This tool, which appears to do nothing, actually enables models to leverage their tool-calling training to pause and think through complex problems, resulting in significant performance improvements.
3. Be specific
Actual agent interactions show the dramatic difference between vague and specific prompts. Consider the following two examples:
File organization gone wrong (or right)
If you need to organize test files that are scattered throughout a project, a vague prompt like, “Organize my test files,” results in the following agent response:
⏺ Bash(find . -type f -name "*.test.*" -o -name "*.spec.*")⏺ Bash(mkdir -p __tests__ tests src/__tests__ src/tests)⏺ Bash(mv src/api.test.js __tests__/ && mv src/user.test.js __tests__/)✓ JavaScript tests → __tests__/✓ Python tests → tests/The agent creates a flat __tests__ directory and dumps all JavaScript test files there, losing the original folder structure and mixing component tests with utility and API tests.
You can get a better agent response by using a more specific prompt:
Find all files ending in .test.js, .test.tsx, .test.py, and .spec.js in the src folder and move them to __tests__ directories that mirror the original folder structure. For example, src/components/button.test.tsx should move to src/components/__tests__/button.test.tsx.This improved prompt results in an improved agent response:
⏺ Search(pattern: "src/**/*.test.js") - Found 3 files⏺ Bash(mkdir -p src/__tests__ src/components/__tests__ src/utils/__tests__)⏺ Bash(mv src/components/button.test.tsx src/components/__tests__/)✓ src/components/__tests__/button.test.tsx✓ src/utils/__tests__/helpers.spec.js✓ Preserved folder structureThe lesson: Both prompts “worked” but the vague one made assumptions that might not match your needs. The specific prompt guaranteed the exact structure you wanted.
The units confusion that costs real money
In this scenario, you run a website CMS platform with subscriptions ($29-99/month) and setup fees ($150-300), and your payment processor stores amounts in cents (standard practice). You need to batch payment transactions from a CSV file:
customer_id,amount,reference1001,2900,CMS-BASIC-JAN1002,15000,SETUP-FEE-NEW1003,9900,CMS-ENTERPRISE-JANWhen you use the following vague prompt, you don’t get the desired result:
I have a CSV file with subscription payments. Please batch these orders with a daily limit of $2,000 per batch.The agent responds to the vague prompt as follows:
# Agent code:amount = int(row['amount']) # Treats 2900 as $2,900!if current_total + amount > 2000: # $2,900 > $2,000 # Creates new batch for EVERY transactionThe agent creates 30 batches (one per transaction since even the “basic” plan exceeds $2,000).
You use the following, more specific prompt instead:
I have a CSV file with subscription payments. The amount column contains values in cents (e.g., 2900 = $29.00). Please batch these orders with a daily limit of $2,000 (200000 cents).When given the improved prompt, the agent delivers the correct result:
# Agent code:amount_cents = int(row['amount'])amount_dollars = amount_cents / 100 # Converts 2900 → $29.00if current_total_dollars + amount_dollars > 2000: # Batches properlyIt creates three batches with proper grouping.
The lesson: A human sees “2900” for a “BASIC” plan and immediately thinks “$29”. An agent might interpret it as “$2,900” - who pays that for basic website hosting? Without explicit units, you’re gambling on the agent’s interpretation.
4. Create custom user rules in a convention file
The practice of creating AI convention documents (like CLAUDE.md) has become increasingly popular. These files act as persistent rules that agents follow automatically.
For example, an agent implements different code styling based on whether it’s using a convention document in addition to user prompts or relying on user prompts alone.
When you prompt Claude to “refactor cart.js to modern JavaScript” without including any style rules in CLAUDE.md, it makes its own decisions. It might use class syntax, skip documentation, or add features you didn’t ask for.
However, when you include the following section in CLAUDE.md, Claude will respond to the same “refactor cart.js to modern JavaScript” prompt by converting function declarations to arrow functions and adding JSDoc comments, because it follows the CLAUDE.md rules automatically:
## Code Style Rules- Use arrow functions instead of function declarations- Use const/let instead of var- Add JSDoc comments to all exported functionsThis example makes the power dynamic clear: When the same instruction appears in both CLAUDE.md and your prompt, CLAUDE.md usually wins. Use this to your advantage for consistent project-wide rules.
One developer’s observation on Hacker News demonstrates how project-specific guidance significantly improves agent performance:
I have a rule: ‘Do information gathering first,’ which encourages it to look around a bit before making changes.
5. Learn real-world safety from production disasters
The Ory team documented a sobering incident where an AI agent accidentally deleted their production database. Here’s what actually happened and how you can prevent similar disruptions:
When Ory sent a prompt telling the agent to “Fix the database connection issue in production,” the agent responded as follows:
⏺ Agent connected to production database⏺ Attempted to "fix" by dropping and recreating tables⏺ Production data: goneIf they had given the agent a prompt like the following, they could have prevented the disaster:
Set up these safety rules in your CLAUDE.md or agent configuration:- Before making any changes, confirm the environment (test vs production).- Never modify production databases directly.- Require explicit confirmation for destructive operations.- Given the option, use read-only credentials by default.The lesson: Agents don’t understand the difference between “test” and “production” unless you explicitly tell them. Always assume they’ll take the most direct path to “fixing” something.
6. Practice constraint-based prompting
Instead of explaining in natural language, stub out methods and define code paths directly in code:
def process_data(input_file: str) -> pd.DataFrame: """TODO: Implement data processing 1. Load CSV file 2. Clean missing values 3. Normalize numeric columns 4. Return processed dataframe """ pass # AI: implement this function following the docstring7. Use AI to improve your prompts
The fastest way to fix a broken prompt is to use AI itself. Instead of guessing what went wrong, request specific feedback about why the prompt failed.
This works because the agent:
- Understands its own failure modes better than you do.
- Can identify ambiguities you missed.
- Suggests concrete improvements, rather than giving vague advice.
You can use an agent like Claude or ChatGPT directly by pasting your failed prompt in the console and asking for analysis.
Alternatively, you can use agent-specific tools to improve a prompt. For example, the Workbench page in the Anthropic console contains various tools for bettering prompts.
You can optimize your prompts by templatizing them. Make individual prompts reusable by clicking on the Templatize button.
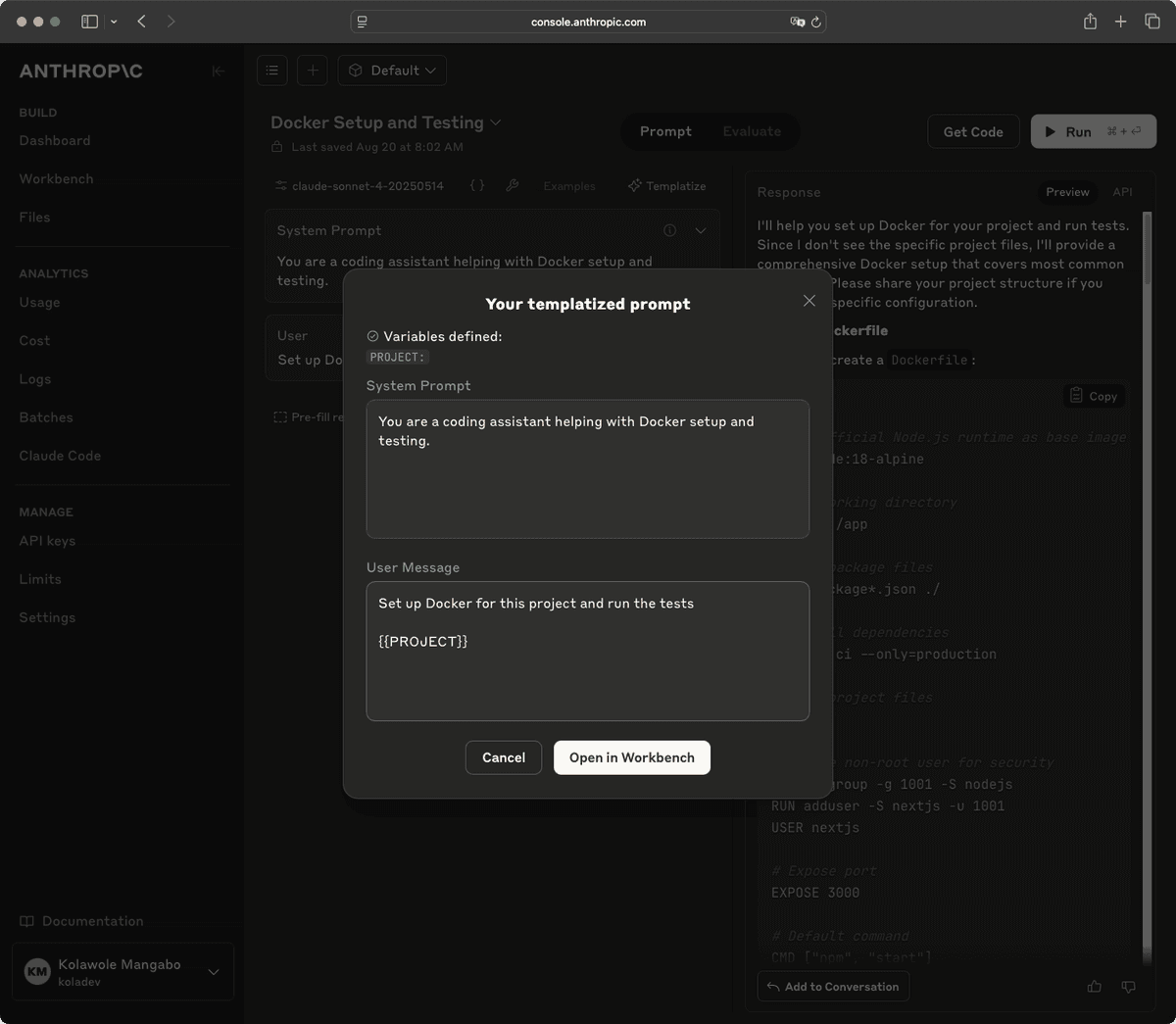
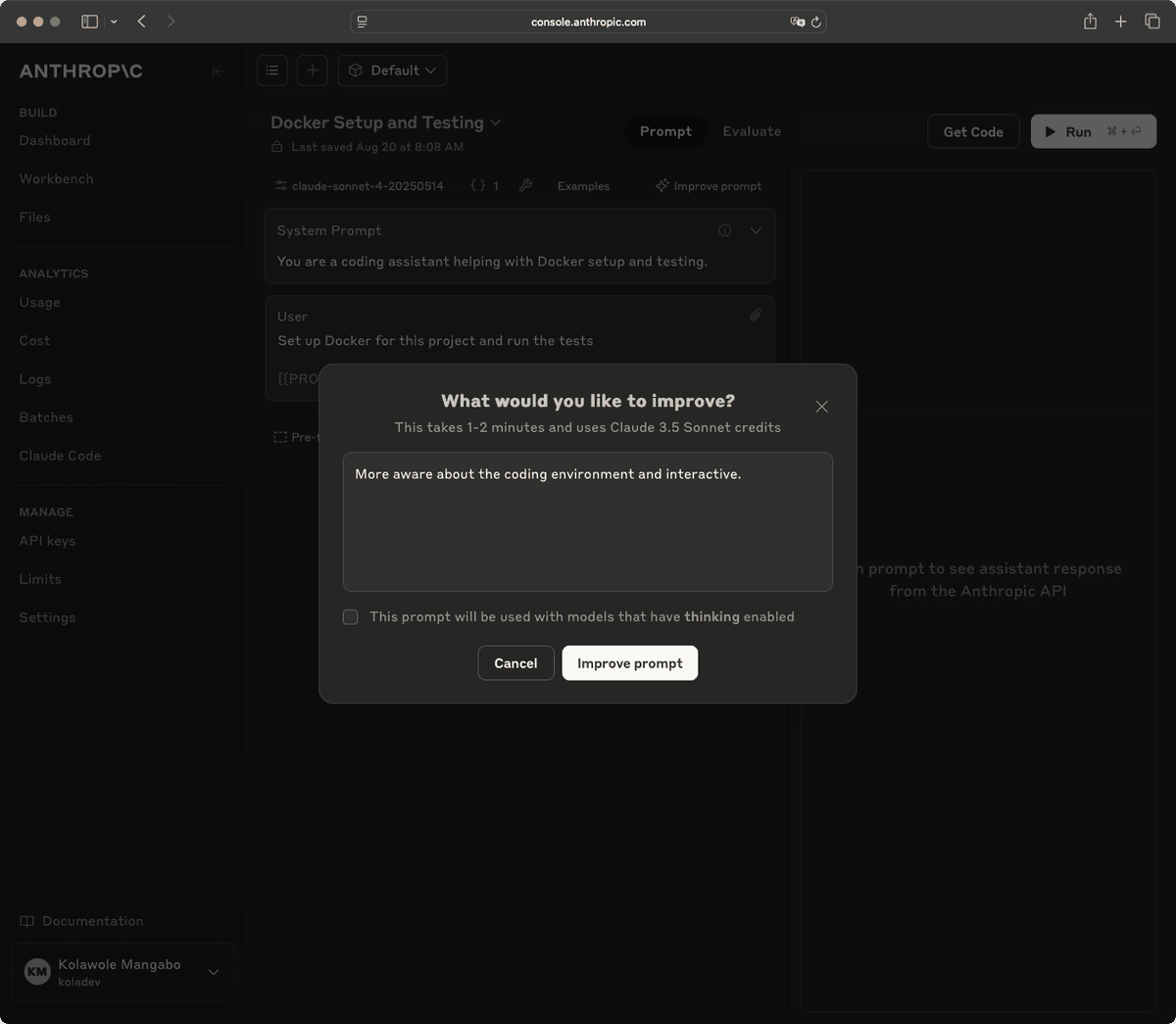
You can also use the Improve prompt button to interactively develop a prompt via the What would you like to improve? modal.
Once you’ve stated your needs, Anthropic provides you with an updated prompt:
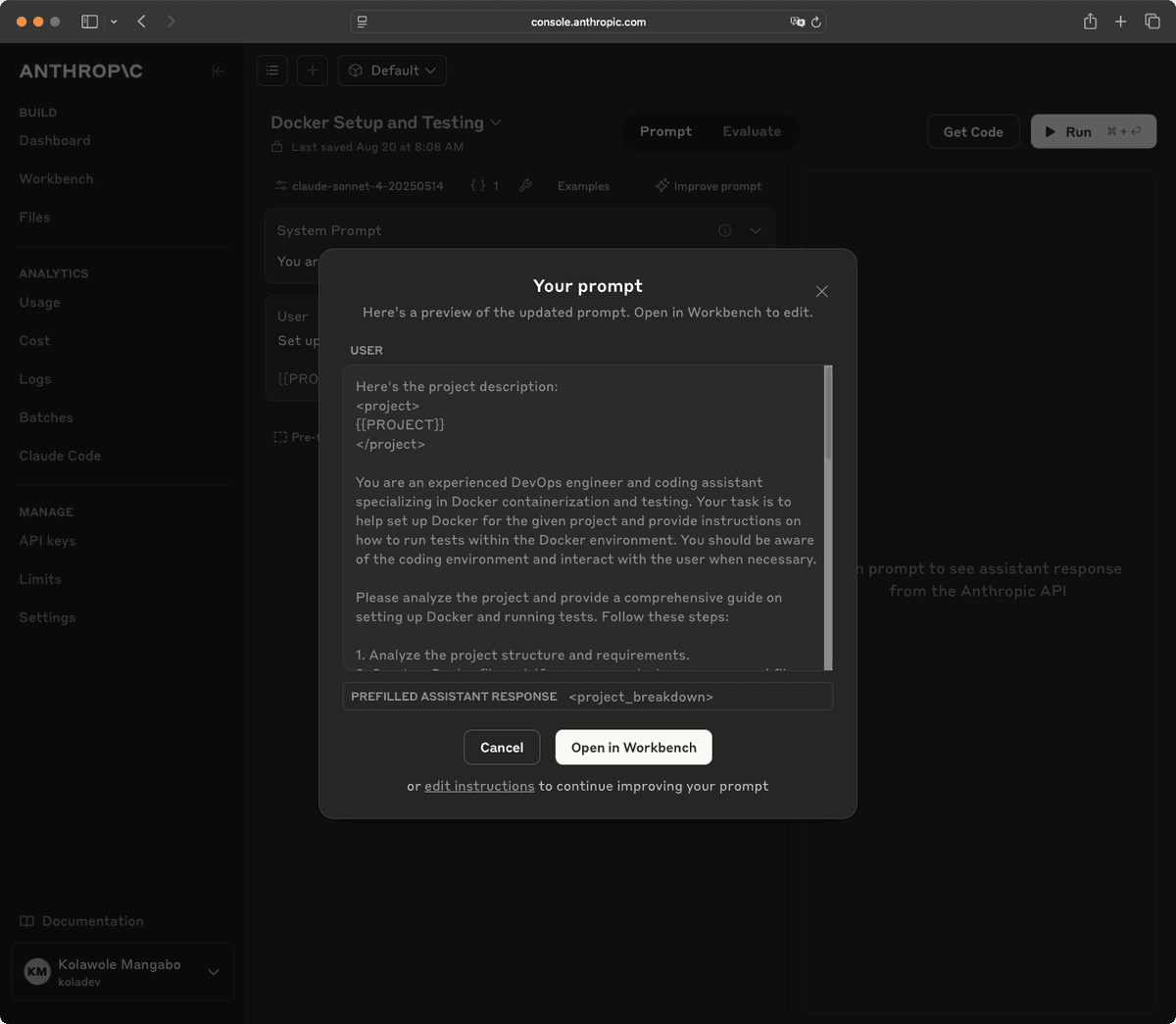
We tested this process with the following initial prompt:
Set up Docker for this project and run the tests
{{PROJECT}}And we ended up with the following prompt, improved by Anthropic tools:
Here's the project description:<project>{{PROJECT}}</project>
You are an experienced DevOps engineer and coding assistant specializing in Docker containerization and testing. Your task is to help set up Docker for the given project and provide instructions on how to run tests within the Docker environment. You should be aware of the coding environment and interact with the user when necessary.
Please analyze the project and provide a comprehensive guide on setting up Docker and running tests. Follow these steps:
1. Analyze the project structure and requirements.2. Create a Dockerfile and, if necessary, a docker-compose.yml file.3. Provide instructions for building the Docker image and running the container.4. Explain how to run tests within the Docker environment.
Before providing the final guide, wrap your thoughts inside <project_breakdown> tags to break down your thought process. In this section:- List out the key components of the project- Identify potential dependencies- Consider any specific testing requirements- Note any potential issues or questions you might need to ask the user
If you need any clarification about the project, ask the user before proceeding.
In your final response, structure your guide as follows:
1. Project Analysis2. Dockerfile Creation3. Docker Compose Setup (if necessary)4. Building and Running the Docker Container5. Running Tests in Docker6. Troubleshooting Tips
For each step, provide clear explanations and reasoning for your choices. If there are multiple possible approaches, explain the pros and cons of each.
Remember to be interactive and ask for clarification if any aspect of the project is unclear or if you need more information to provide accurate instructions.
Now, please proceed with your project breakdown and guide creation.This tool was built for Anthropic models and agents, but the same pattern works with others. You can ask ChatGPT, Gemini, or any LLM to refine your prompt by following the flow: Your prompt → Goal → Refined prompt.
8. Use XML tags in prompts
XML is token-rich compared to JSON or YAML: Lots of angle brackets and closing tags create strong, distinct boundaries. These clear boundaries help LLMs avoid mixing sections. LLMs aren’t actually parsing in the strict sense, like a compiler. They’re predicting tokens.
By providing an LLM with consistent delimiters (<tag>…</tag>), you enable it to do the following:
- Recognize scope easily: The
<inputs>section is clearly different from<outputs>. - Reduce ambiguity: Instead of “status (optional),” you give
<param name="status" required="false">, and the model no longer needs to infer.
The following example demonstrates how to use XML tags to write a prompt that includes context, the desired format, and constraints:
<context> This is a legacy JavaScript project from 2018 that uses ES5 syntax and jQuery. The team maintains backward compatibility with IE11. </context>
<task specificity="high"> Add input validation to the login form: check for empty email, validate email format, ensure password is at least 8 characters, and display error messages. </task>
<response_format> Respond with only: TESTS: PASS/FAIL, ERRORS: [count], FILES: [list of failing files]. No explanations. </response_format>
<constraints> The files to modify are in the /components directory. Do not install new dependencies. You will find everything you need at /ui and utils.ts. </constraints>As agents get smarter, prompts become more important, not less
Smarter agents make more sophisticated assumptions that are harder to predict and debug. As agents get “smarter,” specific prompts become more important, not less.
Your action items:
- Create a
CLAUDE.md(or equivalent file) for your projects with explicit rules. - Include units, formats, and examples in your prompts.
- Test prompts with actual outputs before trusting them in production.
- When something goes wrong, make your prompt more specific, not longer.
Last updated on