MCP vs RAG
Nolan Sullivan
November 24, 2025 · 14 min read
Ask Claude about Django 5.2’s new features, and you get this:
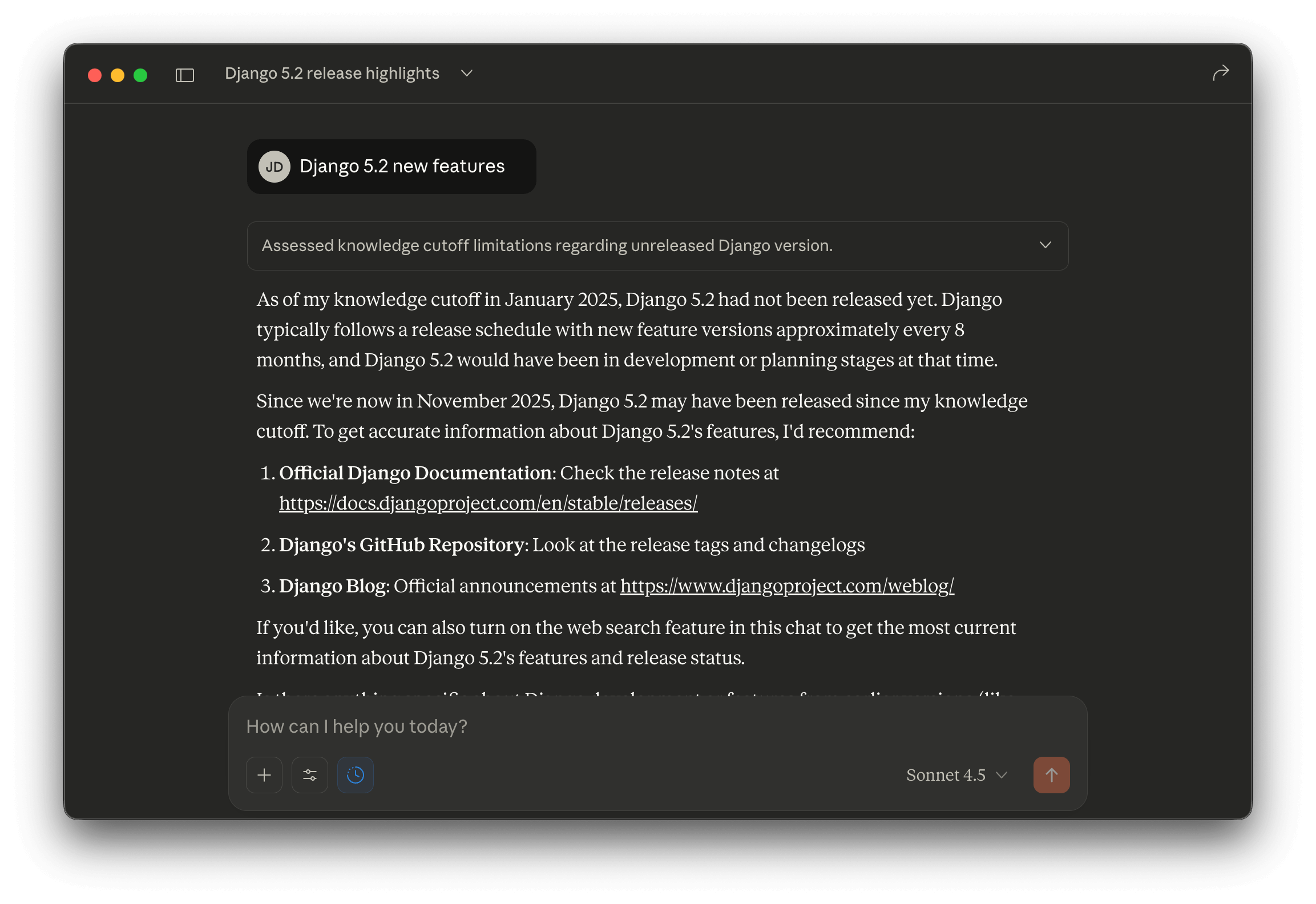
Django 5.2 was released in April 2025. Claude’s training data ends in January 2025, so it doesn’t know about this release yet.
This is the core limitation of LLMs: their knowledge is frozen at training time. They can’t access information published after their cutoff date or domain-specific data locked inside your organization. Claude doesn’t know your API documentation, your company’s internal policies, or yesterday’s product updates.
To bridge this gap, you have two architectural options: Retrieval-Augmented Generation (RAG) or Model Context Protocol (MCP) servers. Both connect LLMs to external information, but they work differently and excel in different scenarios.
This guide compares RAG and MCP through a concrete example: teaching Claude about Django 5.2’s new features. You’ll learn how each approach works, what it costs in tokens, and when to use which.
RAG vs MCP: Different problems, different solutions
RAG is an architecture pattern for semantic search. Documents are embedded into vectors, stored in a database, and retrieved based on semantic similarity to user queries.
MCP is a protocol for connecting LLMs to external systems. It standardizes how LLMs call tools and access data sources, and whether those tools perform RAG searches, query databases, or hit APIs.
They’re not competing approaches. RAG solves issues like, “How do I search documents semantically?” while MCP solves problems like, “How do I connect my LLM to external systems?”
What is RAG?
RAG combines information retrieval with text generation. Instead of relying only on training data, the LLM searches external databases for relevant context before generating an answer. RAG works in three steps:
-
Retrieval: The system sends the user’s question to a retriever, which is usually a vector database like ChromaDB, Pinecone, or Weaviate. The retriever then searches for semantically similar content and returns the most relevant chunks.
-
Context injection: The system adds retrieved information to the LLM prompt.
prompt = f"""You are a helpful nutritional assistant.Here is relevant information from our nutrition database:{context}Based on this information, please answer the following question:{question}Provide a clear answer using only the context above. If the context doesn't contain enough information, say so.""" -
Generation: The LLM generates an answer using both the retrieved context and the question, grounding its response in actual documentation rather than relying on training data alone.
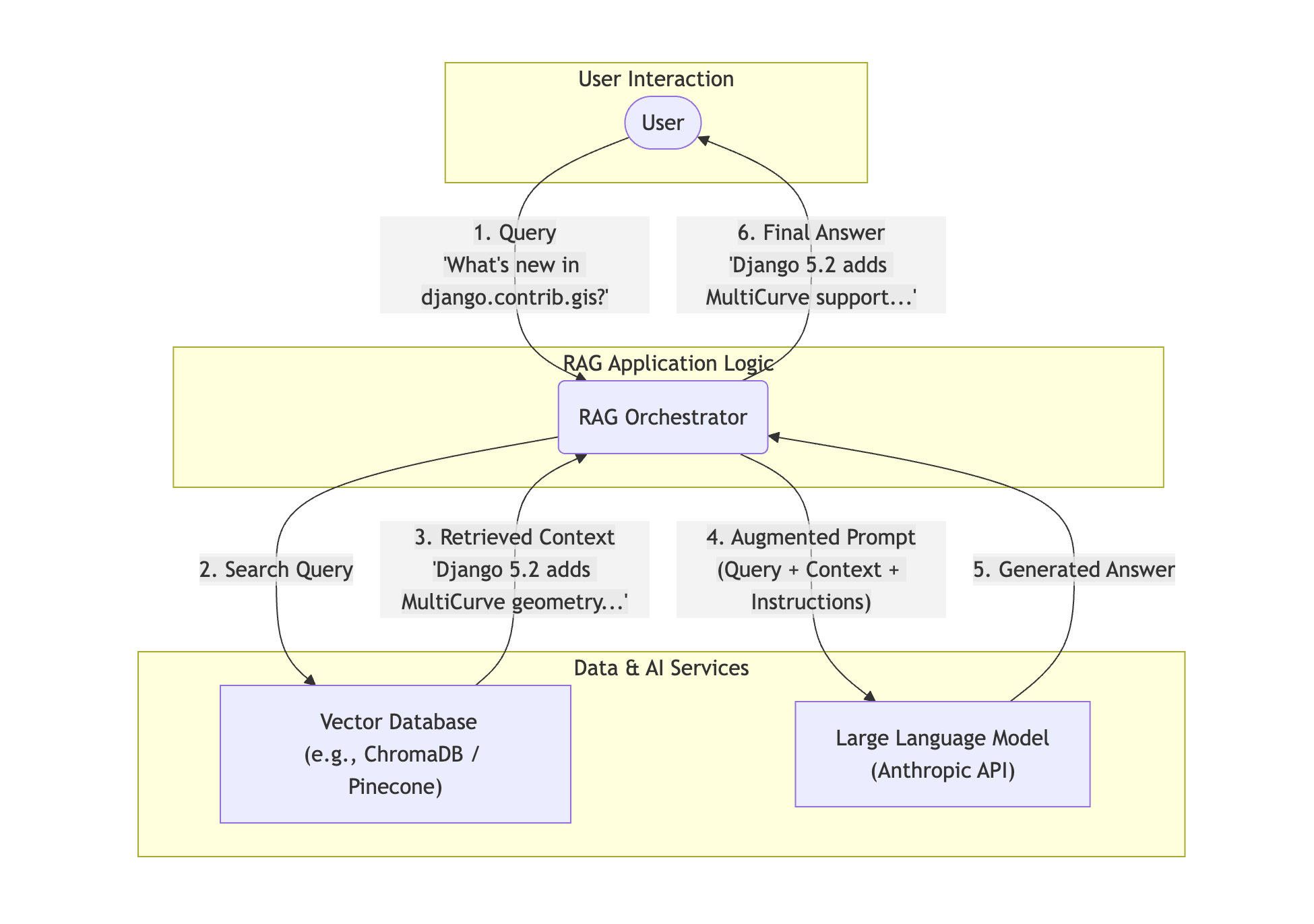
In the diagram above, a user asks, “What’s new in django.contrib.gis?” The query goes to a vector database, which returns relevant snippets like, “Django 5.2 adds MultiCurve geometry.” The LLM receives these snippets with instructions to answer only using the provided documents, resulting in a response like, “Django 5.2 adds MultiCurve support…”
What is MCP?
The Model Context Protocol standardizes how LLMs access external tools and data sources. Without MCP, each LLM provider uses different tool integration methods. Anthropic has tool use, OpenAI has function calling, and each uses its own schema. Building an integration for Claude means rebuilding it from scratch for GPT-5.
MCP provides one consistent interface. An MCP server works with any MCP-compatible system such as Claude, GPT-5, or custom applications. The protocol defines how tools, databases, and APIs get exposed, eliminating the need for provider-specific implementations.
Why is RAG preferred over MCP resources?
To pass documents as context in MCP servers, MCP provides resource primitives that LLMs can consult to enrich their contexts before returning a response. But here is the thing: there is no processing or anything of the document. So, the context is just dumped into the context window, which can easily become bloated.
RAG is then preferred over MCP resources due to the vectorization that makes the document much more digestible, reducing token consumption and saving money in the long run.
RAG vs MCP in practice
Both RAG and MCP can provide Claude Anthropic with Django 5.2 documentation, but in different ways.
Let’s see how RAG and MCP handle the same task of finding information about new features in Django 5.2.
RAG: Semantic search
Building a RAG system for Django documentation requires three components:
- A document processor that extracts and chunks text
- An embedder that converts text to vectors
- A vector database for storage
This implementation uses the PyPDF2 library for PDF extraction, the Sentence Transformers library for embeddings, ChromaDB for vector storage, and Anthropic for answer generation.
Indexing the documentation
The first step is to extract and preprocess the documentation. The following code reads the Django PDF, splits it into overlapping text segments to preserve context, embeds those chunks in vectors, and stores everything in ChromaDB for semantic search:
from pathlib import Pathfrom PyPDF2 import PdfReaderfrom sentence_transformers import SentenceTransformerimport chromadb
pdf_path = Path("django.pdf")reader = PdfReader(str(pdf_path))text = "\n\n".join([p.extract_text() for p in reader.pages])words = text.split()
chunks = [" ".join(words[i:i+500]) for i in range(0, len(words), 450)]embeddings = SentenceTransformer("all-MiniLM-L6-v2").encode(chunks)
client = chromadb.PersistentClient(path="./chroma_db")collection = client.create_collection("django_docs")collection.add(ids=[f"chunk_{i}" for i in range(len(chunks))], embeddings=embeddings.tolist(), documents=chunks)Here, we create 500-word chunks with 50-word overlaps. This overlap is essential because it ensures that concepts spanning chunk boundaries remain intact and searchable. We then convert each chunk into a numerical embedding, which is a 384-dimensional vector that captures its semantic meaning.
The all-MiniLM-L6-v2 model handles this conversion. It’s lightweight and fast, but still maintains good semantic accuracy.
Querying the system
When a user asks a question about Django 5.2, the system embeds the question using the same all-MiniLM-L6-v2 model, retrieves the most relevant chunks from ChromaDB based on semantic similarity, and sends those chunks to Claude. Claude receives the retrieved documentation with instructions to answer using only the provided context.
import osfrom sentence_transformers import SentenceTransformerimport chromadbimport anthropicfrom dotenv import load_dotenv
load_dotenv()
model = SentenceTransformer("all-MiniLM-L6-v2")client = chromadb.PersistentClient(path="./chroma_db")collection = client.get_collection("django_docs")
query = "Django 5.2 new features"q_embed = model.encode(query).tolist()results = collection.query(query_embeddings=[q_embed], n_results=3)context = "\n\n".join(results["documents"][0])
# Send to Claudeclient = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))response = client.messages.create( model="claude-sonnet-4-20250514", max_tokens=1024, messages=[{"role": "user", "content": f"{context}\n\nQuestion: {query}"}])
print("Answer:")print(response.content[0].text)print(f"\nTokens used: {response.usage.input_tokens + response.usage.output_tokens}")The system retrieves the three chunks most similar to the query, and formats them into the prompt along with the question. Claude then generates an answer grounded in the actual Django documentation rather than its training data.
RAG outcome
When a user asks about Django 5.2, the system embeds the query in a vector, matches it against the ChromaDB content, and retrieves the three 500-word chunks most semantically similar to the query:
import osimport anthropicfrom mcp.client.stdio import stdio_clientfrom mcp import ClientSession, StdioServerParametersimport asyncioimport jsonfrom dotenv import load_dotenv
load_dotenv()
async def query_mcp(question: str): # 1. Connect to MCP server server_params = StdioServerParameters( command="python3", args=["mcp_server.py"], env=None )
async with stdio_client(server_params) as (read, write): async with ClientSession(read, write) as session: await session.initialize()
# 2. Call search tool result = await session.call_tool( "search_django_docs", arguments={"query": question} )
return json.loads(result.content[0].text)
# Run queryquestion = "Django 5.2 new features"mcp_results = asyncio.run(query_mcp(question))
# 3. Format results and send to Claudemcp_docs = "\n\n".join([ f"[Page {r['page']}]\n{r['text']}" for r in mcp_results["results"]])
anthropic_client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))response = anthropic_client.messages.create( model="claude-sonnet-4-20250514", max_tokens=200, messages=[{ "role": "user", "content": f"Based on this Django documentation:\n\n{mcp_docs}\n\nQuestion: {question}\n\nProvide a short, direct answer." }])
print("Answer:")print(response.content[0].text)print(f"\nTokens used: {response.usage.input_tokens + response.usage.output_tokens}")The three chunks cover the Django 5.2 release notes, new features, and improvements. They’re semantically related to “new features”, even if they don’t use the exact words used in the prompt. RAG understands that questions about releases relate to feature updates and documentation changes.
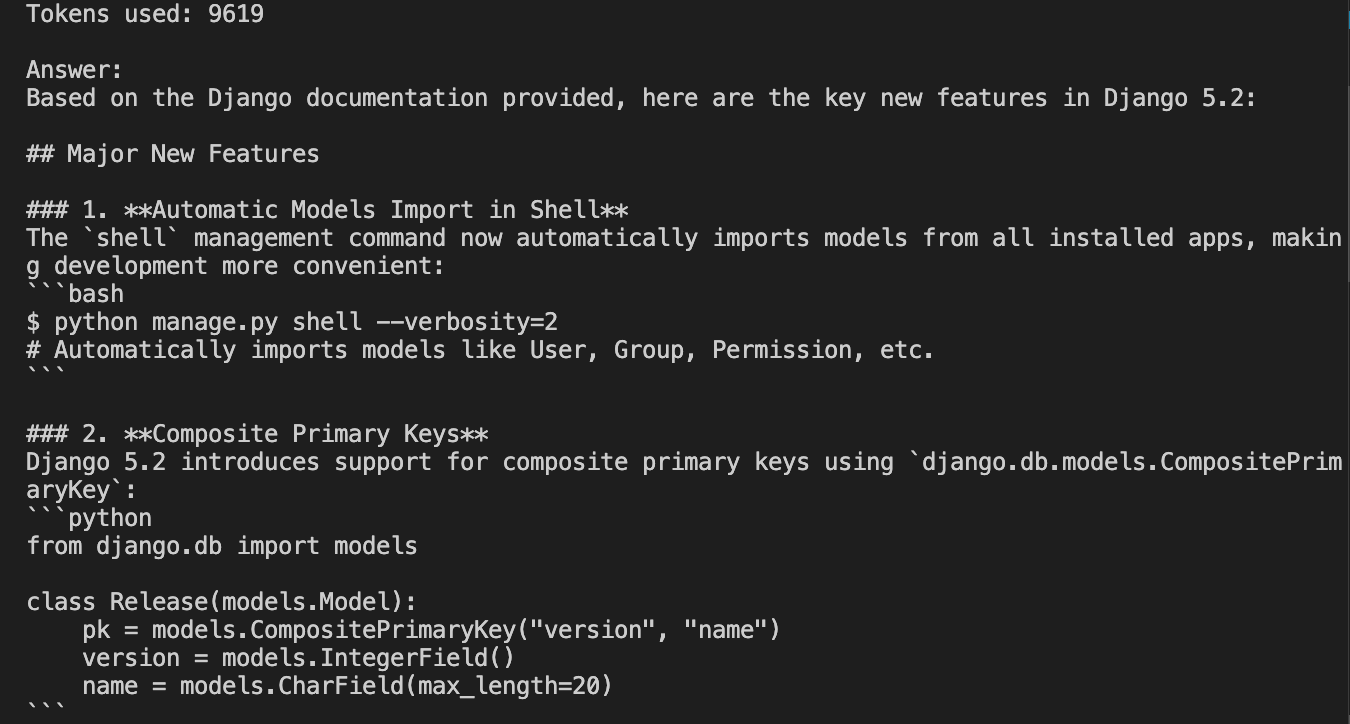
The RAG semantic search uses:
- Tokens: 9,619
- Cost: $0.036
- Response time: 8.89s
MCP: Keyword search
Building an MCP server for Django documentation requires a different architectural approach. Instead of pre-indexing prompts with embeddings, we expose the Django PDF through Tools that Claude can call on demand. MCP servers communicate via JSON-RPC over stdio, making them easy to integrate with Claude Desktop or Claude Code.
MCP data
An MCP server mainly provides two types of primitives:
- Resources are read-only data endpoints (like
django://docs/models). - Tools are callable functions that perform searches, lookups, or actions.
MCP implementation
The server loads the Django PDF once at startup, then provides a search_django_docs tool that performs keyword matching across all pages. When Claude needs information about Django 5.2, it calls this tool with a search query and receives all matching pages as JSON.
#!/usr/bin/env python3"""MCP Server for Django Documentation"""
from pathlib import Pathfrom mcp.server import Serverfrom mcp.server.stdio import stdio_serverfrom mcp.types import Tool, TextContentfrom PyPDF2 import PdfReaderimport json
class DjangoMCPServer: def __init__(self): self.server = Server("django-docs") self.documentation_pages = [] self._load_documentation() self._setup_handlers()
def _load_documentation(self): """Load Django PDF once at startup""" pdf_path = Path("django.pdf") if not pdf_path.exists(): return
reader = PdfReader(str(pdf_path)) self.documentation_pages = [ page.extract_text() for page in reader.pages ]
def _search_documentation(self, query: str, max_pages: int = 50): """Keyword search across all pages""" query_words = query.lower().split() matching_pages = []
for i, page_text in enumerate(self.documentation_pages): page_lower = page_text.lower()
# Check if any query word appears in this page if any(word in page_lower for word in query_words): matching_pages.append({ "text": page_text, "page_num": i + 1 })
if len(matching_pages) >= max_pages: break
return matching_pages
def _setup_handlers(self): """Register MCP tool handlers"""
@self.server.list_tools() async def list_tools(): return [ Tool( name="search_django_docs", description="Search Django documentation and return all matching pages", inputSchema={ "type": "object", "properties": { "query": { "type": "string", "description": "Search query (e.g., 'models', 'authentication')" } }, "required": ["query"] } ) ]
@self.server.call_tool() async def call_tool(name: str, arguments: dict): if name == "search_django_docs": query = arguments.get("query", "") results = self._search_documentation(query)
formatted_results = { "query": query, "results_count": len(results), "results": [ { "page": r["page_num"], "text": r["text"] } for r in results ] }
return [TextContent( type="text", text=json.dumps(formatted_results) )]
return [TextContent( type="text", text=json.dumps({"error": f"Unknown tool: {name}"}) )]
async def run(self): """Start the MCP server""" async with stdio_server() as (read_stream, write_stream): await self.server.run( read_stream, write_stream, self.server.create_initialization_options() )
def main(): import asyncio server = DjangoMCPServer() asyncio.run(server.run())
if __name__ == "__main__": main()The server performs simple keyword matching. When Claude asks about new Django 5.2 features, the server finds all documentation pages containing words like “Django”, “5.2”, “new”, or “features”.
MCP outcome
The MCP server splits the query into keywords, searches for any pages containing those words, and returns up to 50 matching pages:
from mcp import ClientSession, StdioServerParameters, stdio_clientimport asyncioimport json
async def query_mcp(question: str): # 1. Connect to MCP server server_params = StdioServerParameters( command="python3", args=["mcp_server.py"], env=None )
async with stdio_client(server_params) as (read, write): async with ClientSession(read, write) as session: await session.initialize()
# 2. Call search tool result = await session.call_tool( "search_django_docs", arguments={"query": question} )
return json.loads(result.content[0].text)
# Run queryquestion = "Django 5.2 new features"mcp_results = asyncio.run(query_mcp(question))
# 3. Format results and send to Claudemcp_docs = "\n\n".join([ f"[Page {r['page']}]\n{r['text']}" for r in mcp_results["results"]])
response = anthropic_client.messages.create( model="claude-sonnet-4-20250514", max_tokens=200, messages=[{ "role": "user", "content": f"I searched Django docs for: \"{question}\"\n\nFound {mcp_results['results_count']} pages:\n\n{mcp_docs}\n\nProvide a short, direct answer." }])The server returns 50 pages containing words like “Django”, “5.2”, “new”, and “features”. This includes relevant content, such as release notes and feature documentation, alongside many irrelevant pages: configuration files mentioning “new” settings, migration guides with “Django” in headers, tutorial pages with “features” in titles, and 45 other loosely related pages. Claude reads through everything to find the answer.
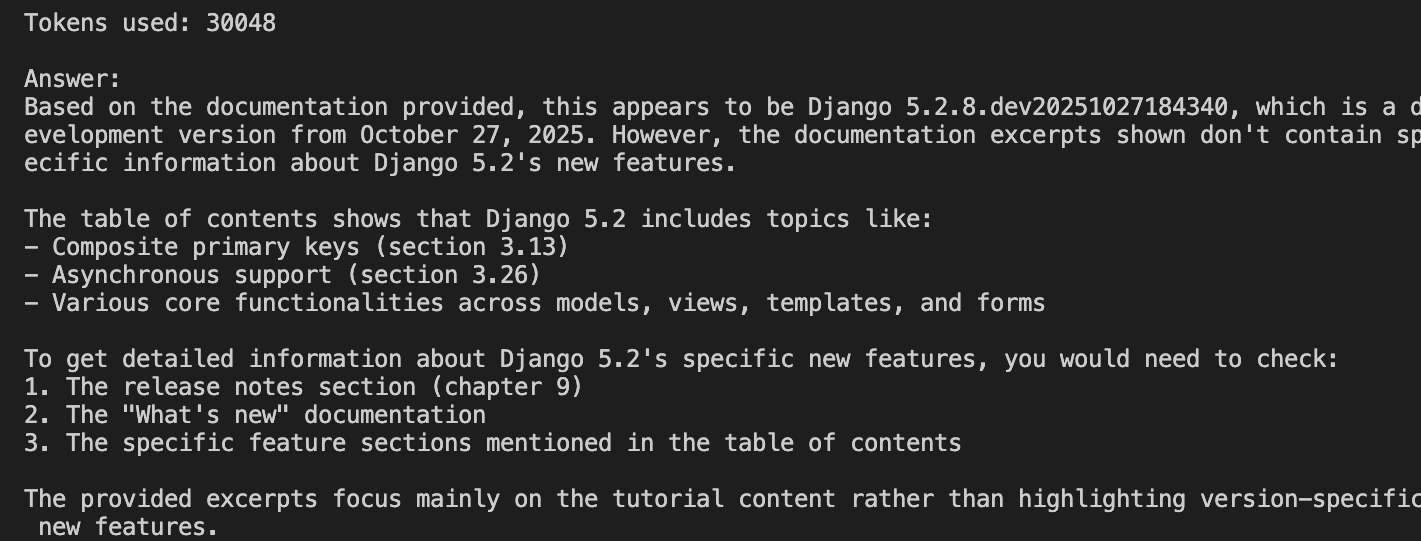
The MCP implementation provided an incomplete answer. The naive keyword search found pages containing “Django”, “features”, “new”, or “5.2” throughout the 2,000+ page document. However, the implementation hit a hard limit: Claude’s API has a maximum context window. The system can only send the first 50 matching pages to stay within token limits.
The most relevant release notes pages weren’t necessarily among the first 50 pages. The keyword matching has no way to prioritize which pages are most relevant because it just returns them in document order. Even if we had unlimited context, sending hundreds of pages per query would be impractical: costs would exceed $9 per query and response times would stretch beyond 90 seconds.
The MCP keyword search uses:
- Tokens: 30,048
- Cost: $0.0925
- Response time: 30.41 seconds
Comparing outcomes
Looking at the resource use for each implementation, it’s clear that RAG is the more efficient option. Generating a response with RAG uses less than a third of the tokens and time it takes with MCP.
| Metric | RAG | MCP |
|---|---|---|
| Input tokens | 9,619 | 30,048 |
| Cost per query | $0.036 | $0.0925 |
| Response time | 8.89s | 30.41s |
This stark difference is due to the use of vectorization in the RAG implementation. By processing documents into chunks and sending only three chunks to Claude, RAG keeps both the token use and the monetary cost of each query low.
In contrast, the MCP server loads the Django document as an MCP resource primitive that is not processed. By passing 50 unprocessed document pages in to the context window, MCP keyword matching uses more than triple the resources of a RAG semantic search.
The RAG implementation also resulted in a more complete answer. Because RAG uses semantic similarity, it provides more focused, relevant context. The embedding model converted the “Django 5.2 new features” query into a vector that’s mathematically similar to vectors for “release notes”, “version updates”, and “feature announcements”, enabling the system to retrieve content based on conceptual proximity.
Without the same semantic reasoning, the MCP keyword search delivered the first 50 pages containing “Django”, “new”, or “features” rather than the 50 most relevant pages containing those keywords.
When to use MCP
MCP shines when working with dynamic, structured data that changes frequently. For example, consider running an e-commerce platform with 100,000+ products. Your prices change daily, the inventory updates in real time, and you constantly add new products.
With RAG, every time something changes, you’d need to re-embed that data and update your vector database. Given your extensive product catalog, you’d need to regenerate embeddings for thousands of items daily. The embedding process alone could cost $5-10 per day and take 10-30 minutes to complete. You’d always have a sync lag between your real data and the data the LLM can access.
With MCP, you could use tools like get_product_info and search_products to access the actual platform data:
@mcp.tool()def get_product_info(product_id: str) -> dict: response = requests.get(f"https://api.yourstore.com/products/{product_id}") return response.json()
@mcp.tool()def search_products(query: str, category: str = None) -> list: return api.search(query=query, in_stock=True, category=category)This pattern works beautifully for any structured data that changes often, including user accounts, order statuses, inventory levels, API rate limits, and server metrics. MCP also enables actions, enabling agents not just to read data but also to create orders, update records, or trigger workflows.
RAG remains the better choice for static content, like documentation, where semantic search matters and the content rarely changes. The ideal architecture often combines both: using RAG to search product documentation and tutorials, and MCP to handle live inventory lookups and order placement.
Combining RAG and MCP
Given their differences, you may think you shouldn’t use RAG and MCP together, but they combine perfectly. In fact, MCP tools can perform RAG queries, acting as the bridge between Claude and your vector database.
For example, instead of Claude directly accessing your vector store, you can build an MCP tool that handles the entire RAG pipeline processes — embedding the query, searching vectors, and returning relevant chunks. From Claude’s perspective, it just calls a tool, but under the hood, that tool conducts a sophisticated semantic search.
@mcp.tool()async def search_documentation(query: str, top_k: int = 3) -> dict: """ Search technical documentation using semantic similarity. Returns the most relevant documentation chunks. """ # 1. Embed the query query_embedding = embedder.encode(query)
# 2. Search vector database results = collection.query( query_embeddings=[query_embedding.tolist()], n_results=top_k )
# 3. Return formatted results return { "query": query, "chunks": [ { "text": doc, "page": meta["page_num"], "similarity": 1 - distance } for doc, meta, distance in zip( results["documents"][0], results["metadatas"][0], results["distances"][0] ) ] }This architecture gives you the best of both worlds. You benefit from RAG’s semantic search and efficient token usage, while MCP provides standardization, discoverability, and easy integration with Claude Desktop and other MCP clients. The vector database stays behind your MCP server, handling the heavy lifting, while Claude simply calls tools when it needs context.
You can even combine multiple approaches in one system, using:
- MCP resources for static reference data (for example, API schemas and configuration files)
- MCP tools with RAG for searchable documentation
- Additional MCP tools for actions like creating tickets or updating records
The MCP protocol unifies all these capabilities in one interface.
The following projects on GitHub implement these patterns:
Conclusion
RAG and MCP aren’t competing approaches; you can use them to complement each other. RAG provides semantic search capability, and MCP standardizes how your AI connects to external systems, whether those systems perform RAG searches, database queries, or API calls.
RAG works best for searching documentation because of its semantic understanding and low token costs. MCP excels at live data queries and actions like creating records and triggering workflows. Modern production AI systems use RAG for searching knowledge bases and MCP for carrying out real-time operations.
Last updated on