Reducing MCP token usage by 100x — you don't need code mode
Chase Crumbaugh
November 18, 2025 · 9 min read
Gram OSS Repository
Check out Github to see how it works under the hood, contribute improvements, or adapt it for your own use cases. Give us a star!
View on GitHubIf you've been following the discussion around MCP (Model Context Protocol) lately, you've probably noticed the grumbling on Hacker News and elsewhere. Critics love to point out that MCP is a "context hog," burning through tokens at an alarming rate when you try to expose more than a handful of tools to an AI agent.
This criticism reveals a fundamental tension in AI tooling: tools are incredibly useful for making LLMs productive, but letting the LLM know about those tools is context-expensive. Load up hundreds of API operations and you'll quickly hit context window limits or face prohibitive token costs.
Lots of people like to complain about the challenges of making LLMs useful and then blame it on MCP. At Speakeasy, we prefer to use the protocol to solve problems. Here are the results.
We've refined our Dynamic Toolset implementation for MCP servers, creating an approach that delivers the best of both worlds: the discoverability of progressive search and the efficiency of semantic search. Our latest benchmarks show up to 160x token reduction compared to static toolsets while maintaining 100% success rates across diverse tasks.
The new Dynamic Toolset approach reduces token usage by an average of 96% for inputs and 90% for total token consumption, making it practical to build MCP servers with hundreds of tools without overwhelming the LLM's context window. Dynamic Toolsets are available in Gram today for all MCP servers!
Learning from our previous approach
Earlier this month, we introduced Dynamic Toolsets with two experimental approaches: progressive search and semantic search. Both delivered significant token reductions, but our production experience revealed important insights:
Semantic search was highly effective at helping LLMs find the right tools within large toolsets using embeddings-based discovery. However, it had a critical limitation: LLMs sometimes wouldn't even attempt to search for tools because they had no visibility into what was available. A vague user prompt like "how many deals do we have?" would cause confusion because the LLM had no idea that a "deal" meant a "HubSpot deal" in this context.
Progressive search provided excellent discoverability by including an outline of available tool "categories" in the tool description. This helped LLMs understand what tools were available in the first place, increasing the likelihood that they would attempt to search for tools. However, this categorization depends on the quality of the input Gram Functions or OpenAPI documents. Semantic search doesn't have this limitation.
We also discovered that adding a separate describe_tools function significantly reduced token usage
by allowing LLMs to retrieve input schemas only for tools they intended to use, since input schemas represent a large percentage of total tokens.
Introducing the refined Dynamic Toolset
Our new approach combines the strengths of both methods into a unified system that exposes three core tools:
search_tools: Uses embeddings-based semantic search like our previous approach, but now includes an overview of available tool categories in the description.
The LLM can also apply filters to narrow searches by tags like source:hubspot or hubspot/deals.
This gives the LLM both discoverability and precise search capability.
describe_tools: Provides detailed schemas and documentation for specific tools. By separating this from search,
we optimize token usage since very large input schemas are only loaded when actually needed.
execute_tool: Executes the discovered and described tools. This remains unchanged but benefits from the improved discovery mechanisms.
The key insight is that tool descriptions provide structure and discoverability, while semantic search provides efficiency and natural language discovery. Together, they create a system that scales naturally without sacrificing usability.
Performance results
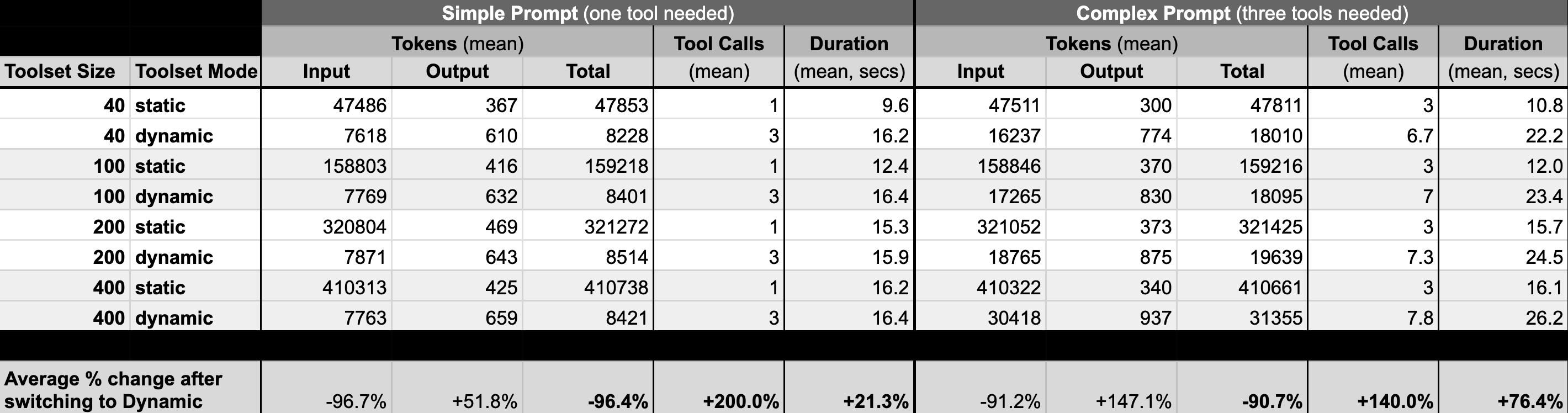
We conducted extensive benchmarking across toolsets of varying sizes (40 to 400 tools) using both simple single-tool tasks and complex multi-tool workflows.
Token usage comparison
Success rates
We saw 100% success rates for all toolset sizes and task complexities, where success is defined as the LLM calling the expected (underlying) tools with the expected arguments. Note that we used Claude Sonnet 4.5 for all tests.
Advantages
The data reveals several significant advantages of Dynamic Toolsets:
Massive token reduction: Input tokens are reduced by an average of 96.7% for simple tasks and 91.2% for complex tasks. Even accounting for increased output tokens from additional tool calls, total token usage drops by 96.4% and 90.7% respectively.
Consistent scaling: Unlike static toolsets where token usage grows linearly with toolset size, Dynamic Toolsets maintain relatively constant token consumption regardless of whether you have 40 or 400 tools.
Perfect success rates: The refined approach maintains 100% success rates across all toolset sizes and task complexities, proving that token efficiency doesn't come at the cost of reliability.
Predictable costs: While tool calls increase by 2x on average, the dramatic reduction in token usage results in overall cost savings, especially for large toolsets where static approaches become prohibitively expensive or impossible due to context window limits.
Disadvantages
More tool calls: Dynamic Toolsets require 2-3x more tool calls than a static toolset.
This is because the LLM needs to search for the tools it needs to use, and then describe the tools it needs to use.
The number of tools calls could be reduced (at the expense of token usage) by combining the search_tools and describe_tools calls into a single call.
Slower: More tools calls means more LLM cycles, which means more time to complete the task. We saw an average of ~50% increased execution time for dynamic toolsets compared to static toolsets. We expect that for longer-running agents, the execution time will be closer to (perhaps even less than) the static toolset execution time. This is because as tools are discovered (brought into context), the LLM can reuse them without needing new search/describe calls.
Why three tool calls instead of one?
While it might seem counterintuitive to increase tool calls, the three-step approach is essential for optimal token efficiency:
search_tools: The LLM first searches for relevant tools using natural language queriesdescribe_tools: The LLM then requests detailed schemas only for the tools it intends to useexecute_tool: Finally, the LLM executes the tools with the proper parameters
This separation prevents loading unnecessary schemas upfront while ensuring the LLM has complete information about the tools it chooses to use. Despite increasing tool calls by 2x, this doesn't increase total tokens or runtime because input tokens are reduced by 96%+.
Tool call patterns
For the "complex" workflow shown in our benchmarks, we typically see 6-8 total tool calls instead of the 3 tool calls required for a static toolset:
Typical 7-call pattern (most common):
- 3 separate
search_toolscalls (one for each needed tool) - 1
describe_toolscall (requesting schemas for all three tools at once) - 3
execute_toolcalls (one for each tool)
Efficient 6-call pattern (when search is optimal):
- 2
search_toolscalls (finding multiple tools in combined searches) - 1
describe_toolscall - 3
execute_toolcalls
Extended 8-call pattern (when search needs refinement):
- 4
search_toolscalls (one search doesn't return expected results, particularly common with larger toolsets) - 1
describe_toolscall - 3
execute_toolcalls
Enhanced search capability: The search_tools function combines semantic search with structured filtering. Tool descriptions include categorical overviews (e.g., "This toolset includes HubSpot CRM operations, deal management, contact synchronization...") while maintaining the precision of embeddings-based search.
Lazy schema loading: Input schemas are only loaded via describe_tools when the LLM explicitly requests them. Since schemas often represent 60-80% of token usage in static toolsets, this separation delivers significant efficiency gains.
Intelligent reuse: The conversation history serves as a "cache" for tool descriptions and schemas, reducing redundant token usage in multi-step workflows.
Why this approach works
The success of the refined Dynamic Toolsets comes from addressing the core tension between discoverability and efficiency:
Context awareness: By including categorical overviews in tool descriptions, LLMs understand what's possible within a toolset before starting their search.
Natural language discovery: Semantic search allows LLMs to describe their intent naturally ("find tools for managing customer deals") rather than guessing exact function names.
Just-in-time loading: Only the tools and schemas actually needed for a task consume tokens, keeping context windows focused and efficient.
Scalable architecture: Adding new tools to a toolset doesn't increase initial token usage, making the approach naturally scalable for growing APIs.
Getting started
Dynamic Toolsets are available in Gram for all MCP servers. To enable them:
- Navigate to the MCP section in your Gram dashboard
- Select your toolset and switch from "Static" to "Dynamic" mode
- Configure any tag-based filters if your toolset includes categorized tools
The system handles the transition automatically, maintaining full compatibility with existing MCP implementations while delivering immediate token efficiency benefits.
The bigger picture
MCP gets a lot of criticism, but here's the thing: it's just an implementation detail. At its core, MCP is a flexible protocol that gets out of the way to let you solve real problems. The complaints you hear aren't really about the protocol—they're about the fundamental challenge of building useful AI agents at scale.
You could build specialized "code mode" environments that sidestep context limitations entirely, and some teams do. But those solutions require significant engineering investment and domain expertise that most teams simply don't have. The beauty of MCP is that it provides a standardized way to make any API accessible to AI agents, and approaches like Dynamic Toolsets show how the protocol can adapt to solve its own scaling challenges.
Dynamic Toolsets represent more than just a token optimization—they demonstrate that MCP can evolve to meet the practical needs of production AI systems. By treating the context window as a resource to be managed rather than a hard constraint to work around, we've opened up new possibilities for building comprehensive AI agents that can work with complex enterprise systems.
The future of AI tooling isn't about building perfect protocols from day one. It's about building flexible systems that can adapt as we learn more about what works in practice. MCP provides that flexibility, and we're just getting started.
Additional reading
Last updated on