Building MCP servers
Designing RAG tools for LLMs
Making documentation consumable by LLMs is one of the most impactful things a developer platform can do. Retrieval-Augmented Generation (RAG) paired with the Model Context Protocol (MCP) is a proven approach: RAG searches your knowledge base efficiently, and MCP standardizes how LLMs access that search.
This guide covers how to design RAG tools for LLMs, from managed solutions to building your own. It demonstrates the input patterns that work, the output structures LLMs need, and the best design choices for RAG tools.
RAG overview
RAG is an architecture pattern for semantic search. It combines information retrieval with text generation, allowing LLMs to search external databases or sources for relevant context before generating an answer.
This usually works by breaking documents into chunks, converting those chunks into vectors, storing them in a database, and then retrieving information based on the semantic similarity to user queries.
Why MCP servers should have a RAG tool
MCP servers provide tools that LLMs interact with to perform actions such as searching databases, calling APIs, and updating records. RAG provides LLMs with additional context by semantically searching the knowledge base. MCP gives LLMs capabilities by connecting them to a system.
For example, a RAG tool could enable your enterprise AI chatbot to answer questions from your user guides and documentation, and MCP tools could help customer support agents retrieve a user’s license information or create a new support ticket. In this example, RAG handles knowledge retrieval and MCP handles your system actions.
The problem with MCP resources
MCP servers provide three primitives: tools, resources, and prompts. MCP resources are designed to give context to LLMs. These resources can be images, guides, or PDFs. MCP resources seem like the natural choice for searching documentation — you expose your docs, and the LLM accesses them.
But the problem is scale. MCP resources dump the entire collection or document into the context window with no processing. If MCP dumps a 100-page product guide in the LLM context, it risks bloating the context and immediately hitting context limits, which could cause timeouts, refusals, or hallucinations. Most LLM clients don’t efficiently search or filter resources from MCP servers, loading them in full rather than selecting relevant sections.
In our RAG vs MCP blog, we compared an RAG implementation to an MCP implementation for searching Django documentation. RAG used 12,405 tokens and found the answer in 7.64 seconds. MCP used more than double that number of tokens (30,044) and took over four times longer (33.28 seconds) than RAG, but still failed to find the answer because the relevant content fell beyond the first 50 pages it could fit in the context window.
How RAG tools solve context bloating
This is where RAG tools come in handy. Instead of an LLM loading, managing, and searching multiple MCP resources, it can call a RAG tool with a natural language query. The tool handles embedding, vector search, and relevance filtering, and returns only the chunks most relevant to the search. The LLM gets precisely what it needs without managing the search infrastructure.
RAG tools also enable features that don’t work with static resources, including:
- Relevance scoring: LLMs can request more context when scores are low.
- Metadata filtering: LLMs can search for specific versions or sections of a resource.
- Context management: You can implement automatic token budgeting.
The following diagram illustrates how this architecture works in practice:
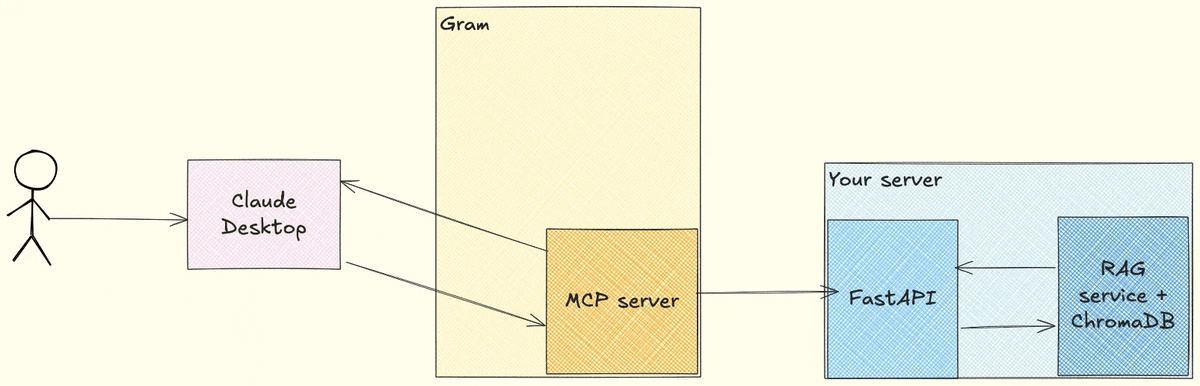
RAG input parameters
A well-designed RAG tool needs three types of parameters: the search query itself, result controls, and quality filters. If an LLM uses incorrect parameters, it could fail to express what it needs or be flooded with irrelevant results.
The query parameter
The query parameter should actually be a natural language query, not a list of keywords, because the RAG system uses embeddings for semantic search, and the embedding models (all-MiniLM-L6-v2 or text-embedding-3-small for OpenAI) are trained on natural language sentences, not keyword lists. When a user asks, “How do I work with curved geometries in Django’s GIS module?” the LLM immediately parses the intent (implementation guidance), identifies the domain (Django GIS geometry handling), and understands the context (a how-to question).
Forcing the LLM to translate the natural language prompt into structured keywords like ["django", "gis", "curve"] with filters like {"type": "tutorial"} throws away semantic understanding. The LLM would have to decide which words were keywords and which were context, map natural language to your filter taxonomy, and lose the semantic relationships that make embeddings work. This would give you worse search results and waste tokens.
The result count control
LLMs understand and manage their context windows. In the tool parameters, let the LLM specify how many results it needs. Cap results at 10 to prevent context overflow. Make this parameter optional with a documented default (a default of 3 results works well).
Quality filtering
Not all search results are equally relevant, so you should allow the LLM to filter by quality.
For example, when you query a vector database like ChromaDB configured to use cosine distance, it returns results ranked by how semantically close each document embedding is to the query embedding. Converting cosine distance to a similarity score (using similarity = 1 - distance) gives a value between -1 and 1, where 1.0 means the query and embedding have identical semantic meanings, 0.5 means they are somewhat related, and 0.0 means they are unrelated.
This keeps low-quality results out of the LLM’s context window entirely. When Claude asks for min_score=0.7, the RAG tool enforces this at retrieval time and filters out anything below that threshold.
The LLM uses these scores to adjust its strategy. If it receives two results with scores of 0.72 and 0.71, it knows the match is marginal, and it may lower the threshold to min_score=0.6 for a broader search. If it gets ten results, all above 0.9, it knows the search is highly targeted.
How to design a RAG tool
If you’re exposing RAG capabilities via multiple endpoints, rather use a single endpoint.
When you have numerous guides or documentation sets to index, you may be tempted to use separate tools or endpoints, but if you’re designing RAG for an enterprise with dozens of products and documentation sets, exposing too many tools to the LLM could result in a tool explosion and cause context bloating. The LLM may face decision paralysis, leading to incorrect tool choices or hallucinations.
Instead, use a single search tool with a collection parameter for specifying which documentation set it should search (for example, collection="user-guide" or collection="api-reference").
Response format
LLMs need results in a format they can immediately use, such as the following:
{ "results": [ { "content": "The actual documentation text...", "source": "https://docs.djangoproject.com/en/5.2/ref/contrib/gis/", "score": 0.87 }, { "content": "More documentation text...", "source": "https://docs.djangoproject.com/en/5.2/releases/5.2/", "score": 0.82 } ], "total_found": 2, "tokens_estimate": 1847}The response format will vary depending on your case, but you should follow these best practices:
-
Use flat results arrays: Don’t nest results in complex structures because the LLM iterates through them sequentially.
-
Return content first: Put the actual text in
content, nottext,document, orchunk. -
Include sources: The LLM needs to cite its sources. URLs, page numbers, or document IDs work.
-
Expose scores: Let the LLM judge result quality. If all scores are below
0.6, it knows the search was weak and might rephrase the query. -
Provide token estimates: This is critical for context management. The LLM needs to determine whether it can fit these results, along with its reasoning, in the context window. Divide the total number of characters by four for a rough estimate (this works well for English documentation).
-
Avoid returning too much data to the LLM:
// ❌ Bad: too much metadata{"results": [{"content": "...","metadata": {"chunk_id": "abc123","embedding_model": "all-MiniLM-L6-v2","embedding_dimensions": 384,"created_at": "2025-01-15T10:23:45Z","database_shard": "shard-3","index_version": "v2.1"}}]}
Error responses for RAG tools
When searches fail, LLMs need actionable errors. Compare the following versions of an error:
// ❌ Bad: Generic error{ "error": "Search failed", "code": 400}
// ✅ Good: Actionable error{ "error": "no_results_found", "message": "No documentation found for 'Djago GIS features'", "attempted_query": "Djago GIS features"}The second version tells the LLM what went wrong (a typo in “Django”) and echoes the query so the LLM can verify the search.
Managed RAG MCP solutions
For most teams, a managed service is the fastest path to making documentation LLM-consumable. These platforms handle embedding, indexing, and serving so teams can focus on content rather than infrastructure.
Speakeasy Docs MCP
Speakeasy Docs MCP generates a self-hosted MCP server from connected git repositories containing markdown documentation. Point it at your file trees, and it ingests the markdown content, constructs a RAG index, and produces an MCP server with two tools: a semantic search tool for RAG-powered queries and a fetch tool for retrieving full documents by path. The generated server is self-hosted, giving full control over where it runs and how it’s accessed.
Inkeep
Inkeep is a platform-agnostic RAG and search layer. It ingests documentation from any platform, then exposes it through a RAG API, an MCP server, or Agent Skills format. Inkeep is used by PostHog, Clerk, and Neon, among others.
Inkeep supports the OpenAI-compatible API format and the Anthropic Citations standard, making it straightforward to integrate with most LLM toolchains. It also offers Agent Skills — a portable format for curated reference documentation that coding agents can consume directly without needing a full MCP server.
Mintlify
Mintlify is an all-in-one docs platform that autogenerates an MCP server for every docs site at the /mcp path. There’s no additional configuration required — publish documentation on Mintlify, and the MCP server is available immediately.
Mintlify uses Trieve for its RAG search layer and also generates an llms-full.txt file for each site. The MCP server is included on the free plan.
Comparison
Build your own RAG tool
When a managed solution doesn’t fit — whether due to custom indexing requirements, private infrastructure, or the need for full control over the search pipeline — building a custom RAG tool is a viable alternative.
Architecture overview
A self-hosted RAG tool has four core components:
- Embedding model: Converts documents and queries into vector representations. Models like
all-MiniLM-L6-v2or OpenAItext-embedding-3-smallare common choices. - Vector database: Stores document embeddings and supports similarity search. ChromaDB, Pinecone, Weaviate, and pgvector are popular options.
- Search API: Accepts natural language queries, runs vector similarity search, and returns ranked results.
- MCP server: Wraps the search API as a tool that LLM clients can discover and call.
Define the search interface
Start by defining schemas that match the input and response format guidelines covered earlier in this article. The following Pydantic models illustrate a clean search interface:
from typing import List, Optionalfrom pydantic import BaseModel, Field
class SearchRequest(BaseModel): query: str = Field( ..., description="Natural language search query", ) max_results: Optional[int] = Field( default=3, ge=1, le=10, description="Maximum number of results", ) min_score: Optional[float] = Field( default=0.5, ge=0.0, le=1.0, description="Minimum relevance score", )
class SearchResult(BaseModel): content: str = Field(..., description="The documentation chunk") source: str = Field(..., description="Source reference") score: float = Field(..., description="Relevance score (0-1)")
class SearchResponse(BaseModel): results: List[SearchResult] total_found: int tokens_estimate: intThe query field accepts natural language directly. The max_results attribute, capped at 10, prevents context overflow, and min_score defaults to 0.5 for inclusive results while allowing the LLM to raise the threshold when it needs higher confidence.
The SearchResponse schema keeps results in a flat array for easy LLM iteration. The score field lets the LLM judge result quality and adjust queries. The tokens_estimate attribute helps with context window management, which is critical for preventing overflow.
Note: Token estimation divides the total number of characters by four, because most tokenizers average about four characters per token in English.
Build the RAG search logic
The core search logic handles embedding the query, running vector similarity search, filtering by score, and estimating token usage:
from sentence_transformers import SentenceTransformerimport chromadb
class RAGService: def __init__(self, chroma_path: str, collection_name: str): self.model = SentenceTransformer("all-MiniLM-L6-v2") self.client = chromadb.PersistentClient(path=chroma_path) self.collection = self.client.get_collection(collection_name)
def search(self, query: str, max_results: int, min_score: float): # Generate query embedding query_embedding = self.model.encode(query).tolist()
# Retrieve extra candidates to account for score filtering search_results = self.collection.query( query_embeddings=[query_embedding], n_results=min(max_results * 3, 50) )
# Convert cosine distances to similarity scores documents = search_results["documents"][0] distances = search_results["distances"][0] ids = search_results["ids"][0]
results = [] for doc, distance, doc_id in zip(documents, distances, ids): score = 1.0 - distance if score >= min_score: results.append(SearchResult( content=doc, source=doc_id, score=round(score, 3) ))
# Sort by score and limit results.sort(key=lambda x: x.score, reverse=True) total_found = len(results) filtered_results = results[:max_results]
# Estimate tokens (rough: 4 chars ≈ 1 token) total_chars = sum(len(r.content) for r in filtered_results) tokens_estimate = total_chars // 4
return filtered_results, total_found, tokens_estimateThe service retrieves max_results * 3 candidates to ensure enough results survive score filtering. When using a vector database configured with cosine distance, the raw results are distances rather than similarities — the conversion 1 - distance produces a similarity score between 0 and 1. Results are filtered by min_score, sorted by score descending, and limited to max_results.
Expose as an API
Wrap the search logic in an HTTP endpoint. The following FastAPI example shows the essential structure:
from fastapi import FastAPI
app = FastAPI(title="Documentation RAG API")rag_service = RAGService( chroma_path="./chroma_db", collection_name="docs",)
@app.post("/search", response_model=SearchResponse)async def search_documentation(request: SearchRequest): results, total_found, tokens_estimate = rag_service.search( query=request.query, max_results=request.max_results or 3, min_score=request.min_score if request.min_score is not None else 0.5, )
return SearchResponse( results=results, total_found=total_found, tokens_estimate=tokens_estimate, )Once the API is running, expose it as an MCP tool using any MCP hosting platform or by building an MCP server directly with an SDK like the MCP Python SDK or MCP TypeScript SDK. The operation_id and description on the endpoint become the tool name and description that LLMs see when discovering available tools.
RAG + MCP: knowledge and agency
RAG and MCP are most powerful when used together. An AI agent might use a RAG tool to search product documentation for implementation guidance, then use other MCP tools to create tickets, update records, or query live data. This combination gives agents both knowledge and agency — the ability to understand context and act on it.
Whether using a managed service or building a custom pipeline, the design principles remain the same: accept natural language queries, return flat arrays with scores and token estimates, and keep the tool interface simple enough that any LLM can use it effectively.